DBMS的演进
本篇我们来回顾下数据库的发展历程,了解下关系型数据库、NoSQL以及最新的NewSQL 、云上数据库演进,方便我们理解当前数据库的设计理念和技术选型。
数据库的发展历史
1960 年代:数据库的诞生
早在 1960 年代,IBM 为了支持阿波罗计划,开发了 IMS 来存储数据,引入了代码与数据分离的思想,让开发者可以专注于操作数据,无需关心这些操作的底层实现细节。
在之后的 1970 年代,作为关系型数据库的先驱,IBM 的 System R 和加州大学的 INGRES 数据库诞生,后者被其他大学广泛使用,并在之后被商业化。与此同时,Oracle 发布了其第一版的 DBMS。
1980 年代:创新与开源
1980 年代,IBM 发布了 DB2 数据库,与此同时还有 Sybase、Informix 等商业产品进入市场,推动着关系型数据库的普及。
在 1980 年代末、1990 年代初,有一股面向对象数据库设计的浪潮,旨在克服关系型数据库和面向对象编程语言之间的不匹配。虽然此类数据库没有成为主流,但在此过程中的许多技术创新为后来 XML 数据存储、对象存储以及 NoSQL 文档数据库的设计奠定了基础。
到了 1990 年代,开源数据库项目兴起,当前最流行的 MySQL 和 PostgreSQL 数据库均在此期间诞生。
2000 年代:互联网推动数据库革新
到了 21 世纪,互联网迅猛发展,互联网应用对高并发和高可用的需求,让传统数据库成为瓶颈。虽然可以通过垂直扩展来解决,但这种方法存在局限性,并且从低配机器向高配机器迁移数据的成本也非常高。
为了克服这些限制,Google、eBay 等公司开始采用 middleware 中间件的方式,将多台机器上的单点数据库组合起来,通过 middleware 做代理,实现跨机器的操作,但这种方式对复杂的查询和事务支持有限,有时候开发者需要自己来维护数据处理逻辑。像 eBay 的 middleware 组件就要求开发者自己实现事务和复杂查询。
总的来看,在互联网带来的需求面前,关系型数据库面临三个问题:
高可用高性能问题:关系型数据库的核心是 ACID,其关注重点在事务一致性和数据的正确性,而这是以可用性和性能为代价的,与互联网应用需要面对的高并发、高可用、高性能的需求不匹配。
数据量问题:与互联网应用一起而来的还有海量的数据,使用像 MySQL 这样的数据库存储海量数据是非常不明智的选择。
数据建模问题:关系型数据库的数据建模和互联网应用所需的数据模型往往并不匹配,有时候需要更灵活、适配的建模方案。 以上问题最终催生了 NoSQL 数据库的诞生。
NoSQL 的崛起
NoSQL 数据库最大的特点就是放弃了对 ACID 强一致性的支持,转而追求最终一致性。数据模型也更加的灵活,比如可以是键值对、文档模型或者图数据库等。NoSQL 指的是 No only SQL,是对非关系型数据的数据存储服务的统称,包括键值存储、文档存储、列存储、图数据库等。
Google的 BigTable、Amazon 的 Dynamo,以及后来的 Cassandra、MongoDB、ElasticSearch 、Redis 等开源产品都可以归类为 NoSQL 数据库。这类数据库通常都是以高可用分布式集群的形式存在,天然支持数据的分片、多副本存储;数据结构上通常使用 LSM-Tree 而不是 B+ Tree 作为实现,从而达到更快的写入速度。
NewSQL 的诞生
NoSQL 数据库虽然解决了传统关系型数据库的很多问题,但同时也带来了新的问题。许多企业应用(如金融系统)要求必须做到强一致性,同时又需要 NoSQL 所带来的高性能、高可用、可扩展性。为此,结合了传统数据库的强一致性和 NoSQL 的高性能、高可用、可扩展特性的数据库应运而生,此类数据库被称为 NewSQL 数据库。
They are a class of modern relational DBMSs that seek to provide the same scalable performance of NoSQL for OLTP read-write workloads while still maintaining ACID guarantees for transactions.
它们是一类现代关系型 DBMS,旨在为 OLTP 读写工作负载提供与NoSQL相同的可扩展性能,同时仍然为事务保持ACID保证。 《What’s Really New with NewSQL?》
New 大致分为三类:
1. 全新架构的数据库
以 Spanner 为代表的,采用新的架构设计,从零开发的新数据库,该类数据库基本都采用了分布式架构,支持跨节点的并发控制和基于副本的容错处理。
大多数情况下,这类数据库不会依赖现成的存储系统或存储引擎,比如 HDFS、Apache Ignite,而是自己实现数据的分布式存储。这样做的好处在于可以让数据库 send the query to the data rather than bring the data to the query,在处理数据量巨大的场景时,可以极大的减少网络流量,提高吞吐性能。
通过自己管理数据存储,数据库还可以实现更加复杂、灵活的副本机制,比如 Aurora 实现的 3 可用区 6 副本的存储形式,这是那些采用现成存储方案的数据库做不到的(比如基于 HBase 的 Splice Machine,基于 Hadoop 的 Trafodion)。
这类采用新架构的 NewSQL 数据库的问题在于,因为是新的产品,使用的人数较少,相关的支持更具也比较缺乏,如果遇到问题可能不容易解决;同时新的数据库如果没有长久的支持,产品可能会中途夭折,导致在推广时阻力也会较大,因此很多数据库均采用了兼容已有数据库的方式,比如 MemSQL 等数据库均兼容 MySQL。
像 Google 的 Spanner 还有 VoltDB、MemSQL、H-Store 等数据库均属于此类 NewSQL。
2. 透明中间件
另一种形式的 NewSQL 与之前的 middleware 处理类似,各个 DBMS 各自独立的部署在多个节点,然后通过实现一个中心化的 middleware 组件来管理数据的存储、查询、副本、事务处理等操作。通常在每个数据节点,还会有一个 shim 程序作为代理与 DBMS 交互,执行具体的查询返回等操作。整个架构和现在的 ServiceMesh 有些类似,通过 middleware、ship 组件的配合,整个集群作为一个逻辑上的数据库对外提供服务。
该种类型的 NewSQL 数据库的最大优势在于可以直接替代当前的数据库且不需要应用做任何的改动,应用层是感知不到数据库的变更的。比如 Oracle 实现的 MySQL proxy 以及 Fabric 工具集,可以帮助我们无缝迁移到 NewSQL。
此类 NewSQL 的问题在于其各个节点运行的依然是传统的 DBMS,比如 MySQL、Postgress 等,这些数据库都是面向磁盘的数据库,在现代高 CPU、高内存的机器下,其实现机制可能导致垂直扩展的能力不足,无法利用好机器的资源。
AgilData Scalable Cluster2, MariaDB MaxScale, ScaleArc, ScaleBase3 等都属于此类 NewSQL。
3. 云上数据库
最后就是云厂商作为云服务提供的 NewSQL,最典型的代表就是 AWS 对外提供的兼容 MySQL 的 Aurora。
对于此类数据库,用户不需要自己维护,同时可以按需伸缩和付费,主打一个有钱可以为所欲为。需要明确的是,只有采用了新架构,同时支持 ACID 以及高可用、高性能、可扩展特性的数据库才会被视为 NewSQL,将 Azure SQL、Google Cloud SQL 这种仅仅提供传统关系型数据库节点管理的并不需要此列。
有兴趣的读者不妨认读下 Aurora 的论文,其基于云计算的特性,将计算和存储相分离,其将计算节点垂直扩展,将存储节点水平扩展,实现了极佳的性能/成本平衡。Aurora 将云上关系型数据库产品推向了一个新的高度。
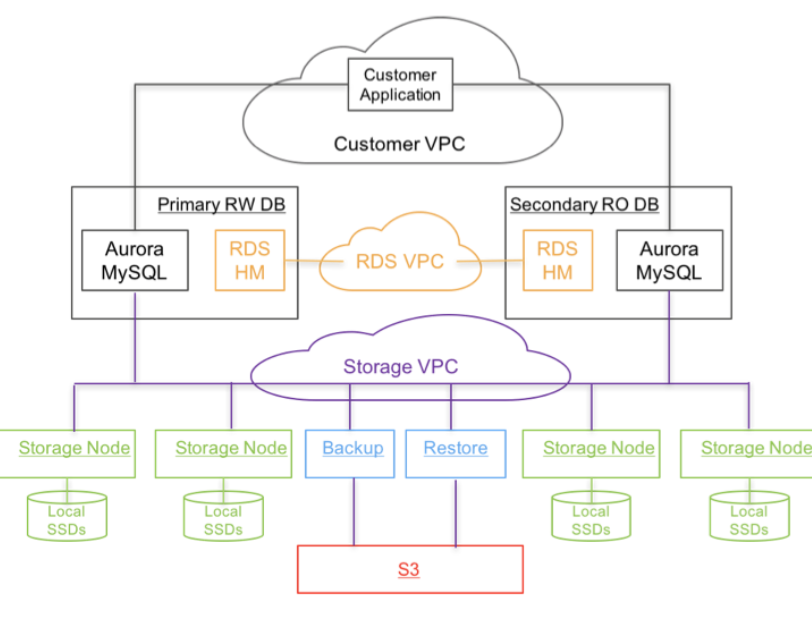
国内阿里云的 PolarDB,以及国产的分布式数据库双雄 TiDB 和 OceanBase 也可以归为此类。
可以看到,发展到今天,数据库的选择已经不再是无脑选择 MySQL 就可以的时代,作为架构师应该深刻理解不同数据库背后的设计思想、实现原理后,才可以做出更加正确的技术选型。