服务整栈编排
服务整栈定义
在微服务架构下,我们需要的不是单个服务,而是有若干服务组成的完整系统。比如一个电商平台,通常包含订单、购物车、商品、用户、支付、物流、网关等服务。
在进行系统部署和管理时,我们需要对整个服务栈进行统一的管理和编排。首先要做的是对整个系统的服务进行整理,梳理出整个服务栈(Stack)信息,一个服务栈的基本信息包括:
- 服务栈的组成:由哪些组件和服务构成。
- 服务栈的版本:服务栈本身的版本和各个组件的镜像版本。
- 组件资源需求:CPU、内存、GPU 等资源配额以及存储、调度需求。
- 组件配置信息:包括环境变量、业务配置、通信证书等。
- 组件的副本数:服务需要运行多少实例。
- 组件依赖关系:比如服务之间的依赖关系,对外部中间件的依赖关系。
- 组件隔离策略:比如网络访问隔离策略。
- 组件伸缩策略:比如根据负载自动扩缩容等。
服务整栈治理
在有了服务整栈定义后,我们就可以准备的一把拉起这个系统,将其部署到分布式集群中去了,但在此之前还需要梳理好组件的状态管理。
像 Kubernetes 管理 Pod 会有 Phase、Condition、ContainerStatus 等状态一样,我们的服务栈和服务组件也需要有相应的状态管理。一个服务栈一般也会有如下状态和操作:
整栈操作
- Bootstrap:拉起整个服务栈。
- Destroy:销毁整个服务栈。
- Scale:扩展某个组件的副本。
- Update:更新服务栈或者某个组件,比如某个组件的镜像。
- Update Config:更新架构中某个服务的配置信息。
- Enable/Disable:人为的停止或恢复某些组件,通常是为了某些测试场景,比如 Chaos。
整栈状态
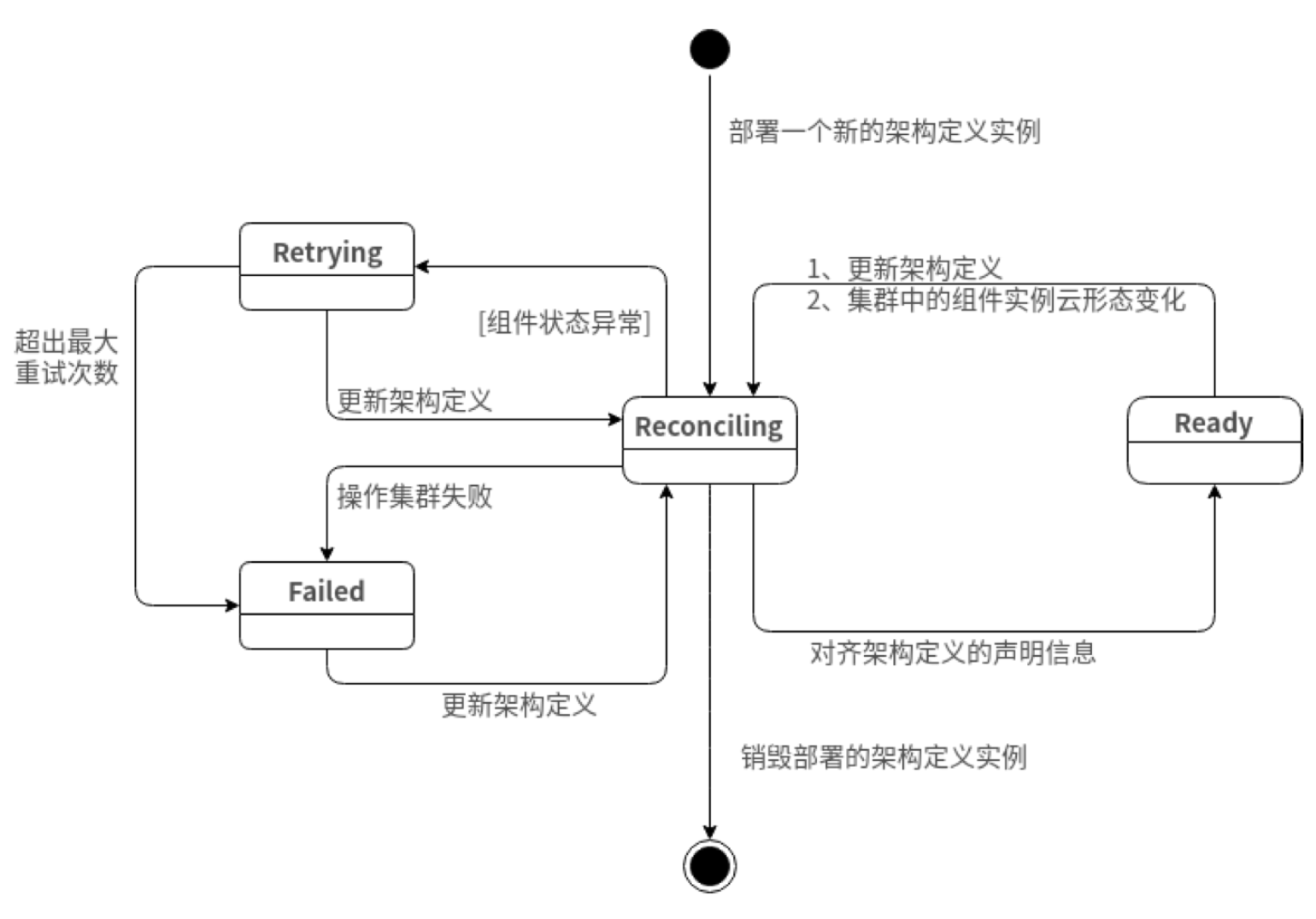
- Ready 就绪状态:服务栈部署成功,所有服务已就绪,可以正常对外服务。
- Reconciling 拟合状态:服务还没有部署启动成功,但也没有明确失败,一般表示正在启动。
- Retry 重试状态:服务部署出现错误,重在重试,一般采用 Back-Off 的方式进行尝试。
- Failed 失败状态:部署过程中发生了不可恢复的故障或尝试次数超过了最大重试次数,宣布部署失败,此时通常需要人工介入修复故障。
- Destroy 销毁状态:服务栈被销毁,所有申请的资源将被释放。
基于上述操作和状态,最终我们需要一个管理平台来对服务进行基于水平触发的拟合治理,使得服务状态达成预期。
服务整栈表示
在梳理完成后,服务栈最好使用类似 Kubernetes API 的声明式语言来对齐进行描述,这样有两个好处:
- 开发人员更容易理解
- 符合
Code as Infrastructure的理念,服务架构代码化,从而做到更加精细的版本控制、变更记录以及相关的 CICD 工作。
在具体工程实践上,笔者见过的大多是基于 Kubernetes 实现状态的水平拟合,以 operator 或 Helm Chart 的方式进行打包部署,当然更多的还是定义一大堆 YAML 文件,通过一键 apply 实现部署。
对于有工程能力的团队,可以在 Kubernetes 之上构建一套自己的服务治理平台,向上对工程人员提供 Stack 定义规范,向下和对接 Kubernetes,将工程人员提交的 Stack 规范转化为 Kubernetes 资源定义,由 Kubernetes 实现服务的部署和管理。这样单个组件的管理由 Kubernetes 实现,而治理平台负责整栈的生命周期管理。
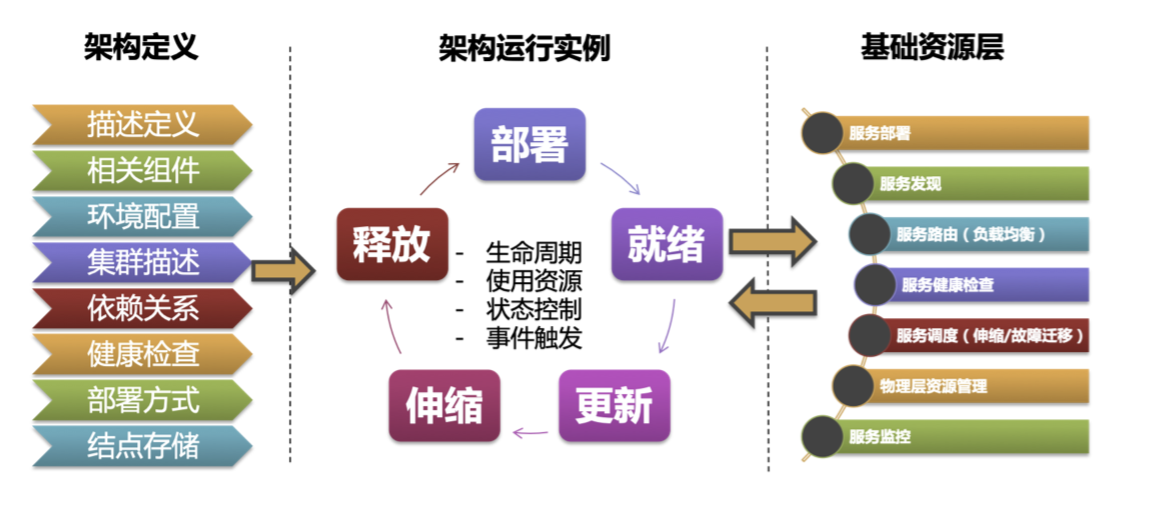
按照笔者实际的经验,这种方式可以极大的简化系统的部署运维复杂度,但服务治理平台本身会成为一个关键点,不仅要满足团队对服务栈的治理需求,还需要兼容 Kubernetes 的不断演进和变化,这会是一个巨大的挑战。