网络原理
Kubernetes 最复杂的部分应该是网络和存储,本篇我们介绍下网络的相关知识,对基于 Flannel 和 Calico 插件的网络通信原理做简要分析。
网络基础概念
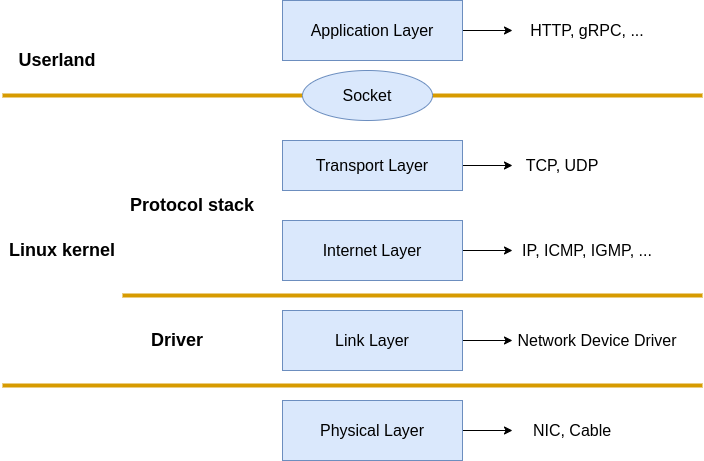
Linux Network Stack
Linux 网络栈示例如下,其符合 TCP/IP 网络模型以及 OSI 模型的理念,网络数据包在链路层、网络层、传输层、应用层之前逐层传递、
Netfilter
Netfilter 是 Linux 内核提供的一个框架,它允许以自定义处理程序的形式实现各种与网络相关的操作。 Netfilter 为数据包过滤、网络地址转换和端口转换提供了各种功能和操作,这些功能和操作提供了引导数据包通过网络并禁止数据包到达网络中的敏感位置所需的功能。
简单来说,netfilter 在网络层提供了 5 个钩子(hook),当网络包在网络层传输时,可以通过 hook 注册回调函数来对网络包做相应的处理,hook 如图所示:
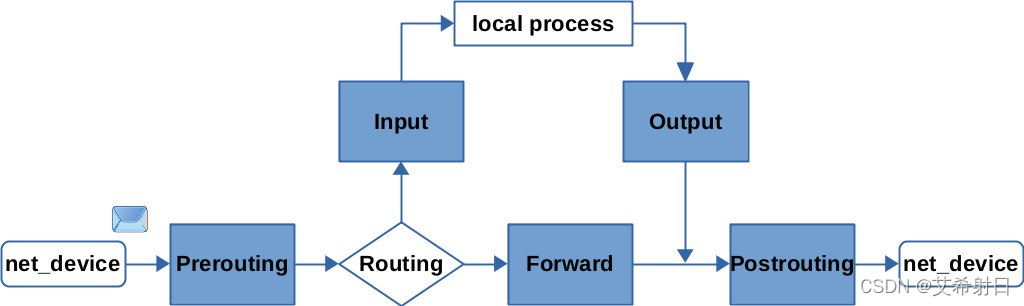
图片来自 Connecting some of the dots between Nftables, Iptables and Netfilter
Netfilter 提供的 5 个 hook 分别是:
PreRouting:路由前触发。设备只要接收到数据包,无论是否真的发往本机,都会触发此hook。一般用于目标网络地址转换(Destination NAT,DNAT)。
Input:收到报文时触发。报文经过 IP 路由后,如果确定是发往本机的,将会触发此hook,一般用于加工发往本地进程的数据包。
Forward:转发时触发。报文经过 IP 路由后,如果确定不是发往本机的,将会触发此 hook,一般用于处理转发到其他机器的数据包。
Output:发送报文时触发。从本机程序发出的数据包,在经过 IP 路由前,将会触发此 hook,一般用于加工本地进程的输出数据包。
PostRouting:路由后触发。从本机网卡出去的数据包,无论是本机的程序所发出的,还是由本机转发给其他机器的,都会触发此hook,一般用于源网络地址转换(Source NAT,SNAT)。
Netfilter 允许在同一个 hook 处注册多个回调函数,在注册回调函数时必须提供明确的优先级,多个回调函数就像挂在同一个 hook 上的一串链条,触发时按照优先级从高到低进行激活,因此钩子触发的回调函数集合就被称为“回调链”(Chained Callback)。
Linux 系统提供的许多网络能力,如数据包过滤、封包处理(设置标志位、修改 TTL等)、地址伪装、网络地址转换、透明代理、访问控制、基于协议类型的连接跟踪(conntrack),带宽限速,等等,都是在 Netfilter 基础之上实现,比如 XTables 系列工具, iptables ,ip6tables 等都是基于 Netfilter 实现的。
iptables
iptables 是 Linux 自带的防火墙,但更像是一个强大的网络过滤工具,它在 netfilter 的基础上对回调函数的注册做了更进一步的封装,使我们无需编码,仅通过配置 iptables 规则就可以使用其功能。
iptables 内置了 5 张规则表如下:
raw 表:用于去除数据包上的连接追踪机制(Connection Tracking)。
mangle 表:用于修改数据包的报文头信息,如服务类型(Type Of Service,ToS)、生存周期(Time to Live,TTL)以及为数据包设置 Mark 标记,典型的应用是链路的服务质量管理(Quality Of Service,QoS)。
nat 表:用于修改数据包的源或者目的地址等信息,典型的应用是网络地址转换(Network Address Translation),可以分为 SNAT(修改源地址) 和 DNAT(修改目的地址) 两类。
filter 表:用于对数据包进行过滤,控制到达某条链上的数据包是继续放行、直接丢弃或拒绝(ACCEPT、DROP、REJECT),典型的应用是防火墙。
security 表:用于在数据包上应用SELinux,这张表并不常用。
上面5个表的优先级是 raw→mangle→nat→filter→security。在新增规则时,需要指定要存入到哪张表中,如果没有指定,默认将会存入 filter 表。另外每个表能使用的链也不同,其关系如图所示:
| Tables\Chains | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| raw | ✅ | ❌ | ❌ | ✅ | ❌ |
| mangle | ✅ | ✅ | ✅ | ✅ | ✅ |
| nat(source) | ❌ | ✅ | ❌ | ❌ | ✅ |
| nat(destination) | ✅ | ❌ | ❌ | ✅ | ❌ |
| filter | ❌ | ✅ | ✅ | ✅ | ❌ |
| security | ❌ | ✅ | ✅ | ✅ | ❌ |
Tables 里列有由上到下代表的 table 的执行顺序,由此我们可以得出处理网络包时,iptables 规则执行顺序:
- 发送到本机的包:
PREROUTING(raw, mangle, dnat) -> INPUT(mangle, filter, security, snat) - 本机路由到其他机器的包:
PREROUTING(raw, mangle, dnat) -> FORWARD(mangle, filter, security) -> POSTROUTING(mangle, snat) - 本地发送到其他机器的包:
OUTPUT(raw, mangle, dnat, filter, security) -> POSTROUTING(mangle, snat)
整理流程如图所示: 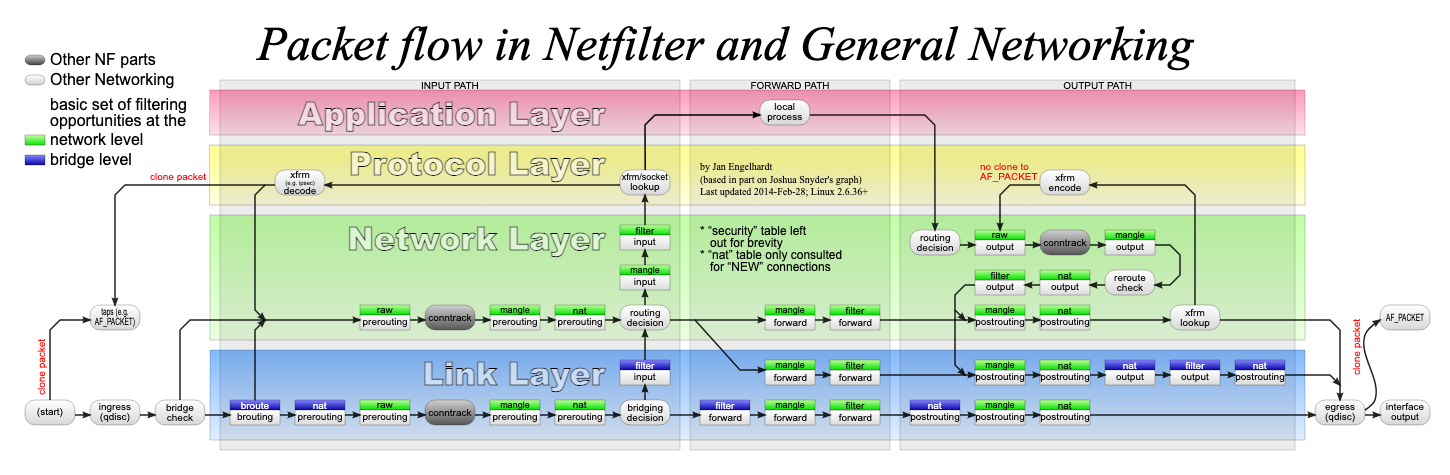
netfilter 和 iptables(以后会还会引入 nfttables)是 kube-proxy 实现基础,通过 ClusterIP 实现由 Service 到 Pod 的通信就是通过 iptables 实现的,本篇后续将详细介绍其通信过程。
IPSet
IPSet 是 Linux 内核提供的 iptables 配套工具,其允许通过 ipset 命令设置一系列的 IP 集合,并针对该集合设置一条 iptables 规则,从而解决了 iptables 规则过多的问题。这样可以带来如下的一些好处:
存储多个 IP 和端口,然后只创建一条 iptables 规则就可以实现过滤、转发,维护方便。
IP 变动时可以动态修改 IPSet 集合,无需修改 iptables 规则,提升更新效率。
进行规则匹配时,时间复杂度由 O(N) 降为 O(1)。
网络虚拟化
虚拟网卡:veth
Linux 内核支持两种虚拟网络设备的方案 TUN/TAP 和 Veth(Virtual Ethernet,虚拟以太网),容器主要是基于 Veth 设备实现网络通信的,因此我们这里只对 Veth 做简单介绍。
使用过网线的同学应该体验过,当我们电脑要联网时,需要将网线的一头插到电脑,另一头插到网孔上。veth 又称为虚拟以太网对(Virtual Ethernet Pair),它就像一根网线一样有两个头,从一个头进来的数据包会直接从另一个头出去。它是在 2.16 版本和网络命名空间一块引入的,旨在解决不同网络 namespace 之间的通信。
两个不同的容器就是两个不同的网络 namespace,veth 就是那根“网线”,一头在这个容器,另一头在另一个容器中,这样两个容器就可以通过 veth 进行通信了,具体细节我们后续会分析。
虚拟交换机:bridge
在物理机网络环境中,如果物理机器较多,每台机器都要单独配置网络的话,管理起来会非常的麻烦,因此引入了交换机,通过交换机将同一网络内的物理机连接起来,实现互相通信。
到了虚拟环境,如果容器较多,需要配置的 veth 对的数量也会急剧增加,因此为了方便管理,自然而然我们也需要一个类似交换机的角色。Linux 2.2 版本就引入了名为 Linux Bridge 的虚拟设备充当二层转发设备,工作机制和物理交换机基本一致。当数据进入 Linux Bridge 时,其根据二层 Frame 的帧类型和目的 MAC 地址做相应处理:
- 如果是广播帧:转发给所有接入网桥的设备。
- 如果是单播帧:查找地址转发表(Forwarding Database),找到目标设备。
- 如果目标设备存在,转发到目标设备。
- 如果目标设备不存在,则洪泛(flood)到所有接入网桥的设备,将响应信息加到自己的地址转发表中。
Linux 最初提供了 brctl 命令来管理 Linux Bridge,但很多新发行版里 brctl 已被淘汰,更推荐用 iproute2 工具(内置,不需要额外安装)来管理,下面是命令示例,后面介绍容器网络通信时还会看到更多操作 veth 和 bridge 的命令。
# 添加网桥
$ sudo ip link add name br0 type bridge
# 查看网桥
$ sudo ip link show type bridge
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether ce:42:63:b6:d8:9c brd ff:ff:ff:ff:ff:ff
10: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 36:fd:3f:5e:f4:52 brd ff:ff:ff:ff:ff:ff
虚拟网络通信:VXLAN
有了物理层的 veth 和基于二层通信的 Linux Bridge,容器网络已经能够轻松的实现本机通信。但如果想在更大规模的分布式系统中进行通信,还需要更高层级的虚拟化才行,否则依赖于物理主机的网络互联在当今时代已经变得不够灵活。
为了解决远程物理网络间的灵活通信问题,人们提出了 软件定义网络(Software Defined Network,SDN) 的理念,其核心思想就是在物理网络之上,通过软件构建出一层虚拟化的网络,从而实现灵活的信息通信和流量控制。被构建出来的网络结构中,位于下层的物理网络被称为 Underlay,负责基础物理网络的管理和互通(三层互通);位于上层的虚拟逻辑网络被称为 Overlay,它用来实现满足上层需求的网络拓扑结构和通信处理。
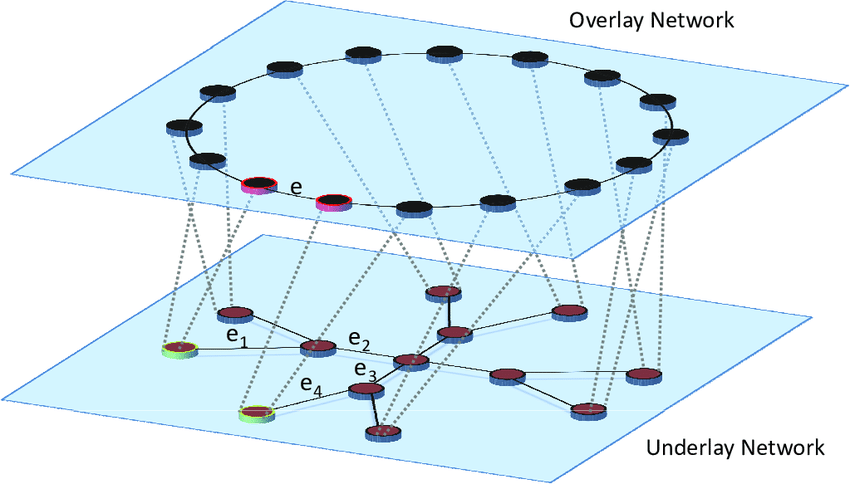
软件定义网络的发展已经有 10 多年的历史了,期间发展出了众多硬件和软件层面的解决方案。由于以 Kubernetes 和 Docker 代表的容器间通信会使用到 Overlay 和 VXLAN 技术,因此这里只对 VXLAN 做简要介绍。
VXLAN(Virtual Extensible LAN)的前身是 VLAN(Virtual Local Area Network,虚拟局域网),其主要用来划分广播域,使得各个广播域实现逻辑隔离,只有域内的机器可以进行二层通信。广播域之间必须通过三层路由进行通信。
假设我们一个物理网络环境内有非常多的机器,机器二层通信时必须携带 MAC 头,一般都是通过 ARP 广播的形式获取目标 MAC 地址。但当环境内机器过多时,就会形成广播风暴,可能会引发严重的网络拥塞,但如果通过 VLAN 实现隔离,广播就只会在虚拟域内进行,从而减少影响。
VLAN 的设计存在两个问题:
VLAN ID 的限制:传统 VLAN 使用12位的VLAN ID,最多支持 4096 个 VLAN,而在大规模数据中心环境中往往需要更多的隔离域。
跨物理网络的限制:传统 VLAN 只能在同一物理网络内进行隔离,无法跨越不同的物理网络进行通信。
为了解决上述问题,IETF 定义了 VXLAN 规范,虽然从名字上好像是 VLAN 的扩展协议,但和 VLAN 只能在二层工作不同,VXLAN 一开始就是为三层网络设计的,它是 Network Virtualization over Layer 3,NVO3,三层虚拟化网络 规范之一,也是最主流的规范。
VXLAN 是典型的 Overlay 网络,通过 MAC in UDP 的报文形式封装数据,其大致流程如下:
- 通信双方支持三层互联,两端都会创建 VETP(VXLAN Tunnel Endpoints,VXLAN 隧道端点)设备。
- 容器发送数据时,原始的二层 Frame 被发送至 VETH,添加 VXLAN Header 封装为 VXLAN 报文。
- VXLAN 报文被主机封装为 UDP 包走正常的 IP 路由发送至目的主机。
- UDP 包达到目的主机,携带的数据,即 VXLAN 报文被 VETP 设备处理。
- VETP 设备解析出原始 Frame 发送至目标容器。
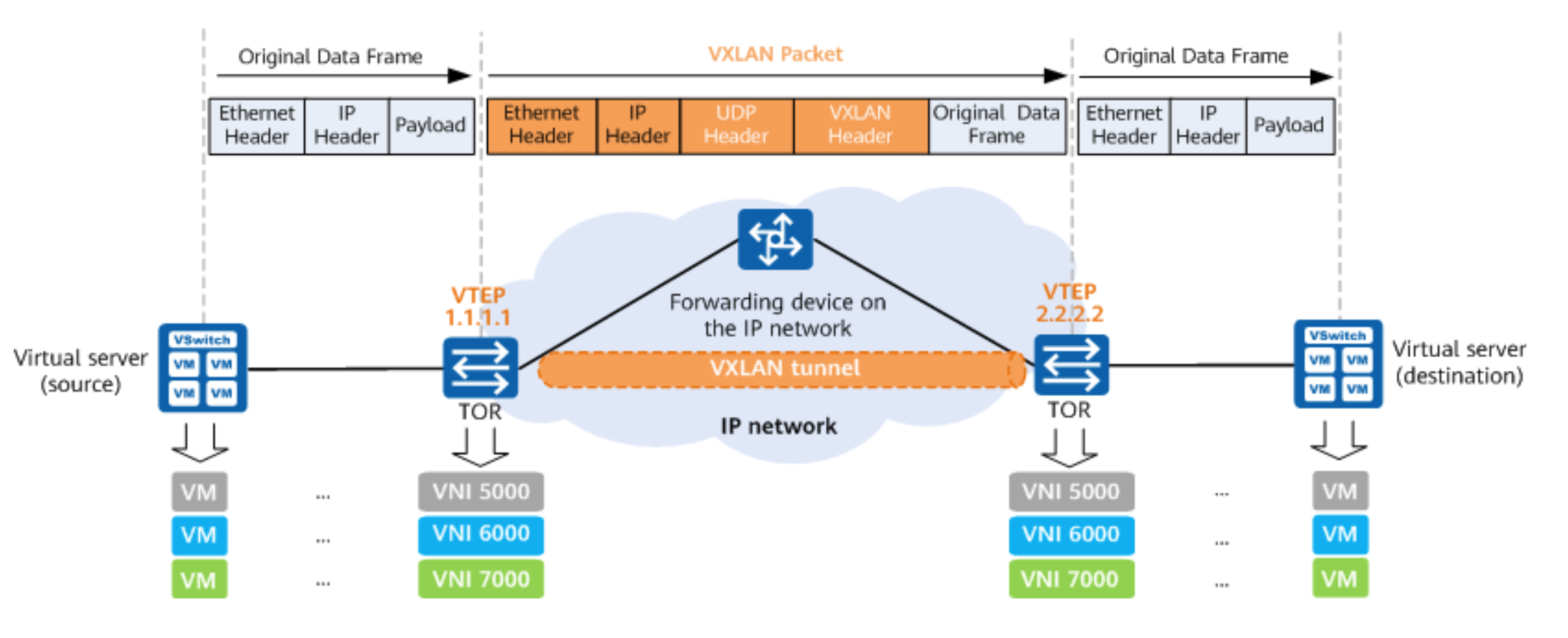
一个更详细的 VXLAN 报文格式如下:
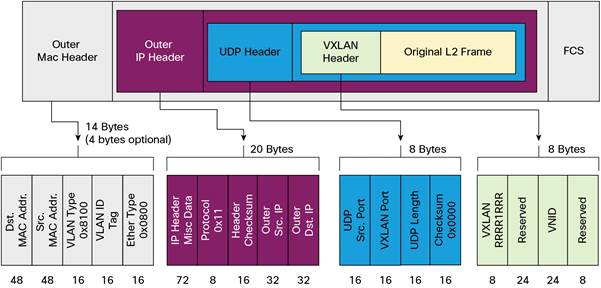
从左到右依次为:
- Outer MAC Header:MAC 头信息,主要包含宿主机 MAC 地址以及下一站的目标 MAC 地址。
- Outer IP Header:IP 包信息,这里主要封装的是宿主机的 IP 和目的主机的 IP 地址。
- UDP Header:UDP 包,主要用于封装 VXLAN 报文,目标端口为 VXLAN Port,一般固定为 4789。
- VXLAN Header:VXLAN 信息,主要字段是占 24 位的 VNI(VXLAN Network Identifier)字段,用于标识 VXLAN 中的不同租户,24 位理论上的最大数量为 2^24 - 1 = 16777215,约为 1677 万。
- Origin Frame:原始帧,由容器发出的二层帧数据包。
Linux 从 3.12 版本开始对 VXLAN 的支持达到完全完备的程度,其具有的高灵活性,可扩展和易于管理等特点:
- VXLAN 使用 24 位的 VXLAN 网络标识符(VNI),理论最多支持 1600 万虚拟网络。
- 完全可以在现有 IP 网络运行,无需对底层网络进行大规模改造。
- 只要数据中心间支持三层通信,就可以通过 VXLAN 建立隧道,实现跨数据中心的灵活通信。
当然,任何方案都是一种 trade-off,VXLAN 在具有上述优势的同时,也会有一些不足:
传输效率不足:从上面的包结构分析中我们看到,报文新增了大约 50byte(Outer MAC Header 14 byte,Outer IP Header 20 byte, UDP Header 8 byte,VXLAN Header 8 byte),在传输大量数据时 50byte 的额外消耗不算什么,但对于小包传递会造成较大的额外开销。
传输性能下降:这是所有需要封包解包的隧道技术的通病,和正常通信相比,传输流程多了 VXLAN 的封包与解包操作,会造成额外的资源消耗和性能损失。
Kubernetes 网络通信
Container To Container
对于 Kubernetes,网络通信的面临四种情况:
- 容器到容器(Container To Container)通信
- Pod 到 Pod(Pod To Pod)通信
- Pod 到 Service(Pod To Service)通信
- 外部到 Service(External To Service)通信
熟悉了上述相关网络概念后,我们先对容器到容器(Container To Container)通信过程进行分析,后面会对其他场景进行讨论。
Docker 容器的网络有 4 种类型:
Bridge :默认的网络模式,使用软件桥接的模式让链接到同一个Bridge上的容器进行通讯。
Host:直接使用本机的网络资源,和普通的原生进程拥有同等的网络能力。
MacVLAN:允许为容器分配mac地址,在有直接使用物理网络的需求下可以使用该网络类型。
Overlay:在多个 Docker 宿主机之间创建一个分布式的网络,让属于不同的宿主机的容器也能进行通讯。
Bridge, Host, MacVLAN 都是本机网络,Overlay 是跨宿主机的网络。当不允许 container 使用网络时,比如生成密钥哈希计算、有相关安全性需求的场景下,可以将网络类型设置成 None,即不允许该容器有网络通讯能力。
我们重点关注 Bridge 网桥模式,Docker 启动时会创建一个名为 docker0 的网桥,同主机上容器之间的通信都是通过该网桥实现的。
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:16:3e:16:3d:ab brd ff:ff:ff:ff:ff:ff
altname enp0s5
altname ens5
inet 172.17.150.182/20 metric 100 brd 172.17.159.255 scope global dynamic eth0
valid_lft 304340421sec preferred_lft 304340421sec
inet6 fe80::216:3eff:fe16:3dab/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:7e:92:97:c9 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:7eff:fe92:97c9/64 scope link
valid_lft forever preferred_lft forever
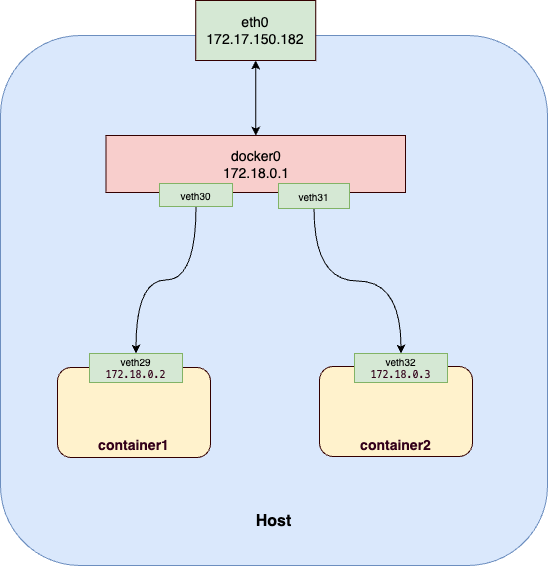
可以看到有 docker0 设备,其 IP 地址为 172.18.0.1/16,这样之后创建的所有容器的 IP 地址都在 172.18.0.0/16 网段下,docker0 是该网段下的第一个地址。
当启动容器后,docker 会通过 Veth(Virtual Ethernet)对将容器和 docker0 网桥连起来,同时修改容器内的路由规则,当 container1 向 container2 发起请求时,基于路由规则会将请求路由到 docker0 网桥,然后在转发到 container2 中。我们使用如下命令创建两个 Nginx 容器,并查看其网络设备:
- 创建容器
$ docker run -d --name nginx1 -p 8080:80 nginx
d0cdb3f0af4fb69c558638d1480dbbbe77239b283a235077a450a1e4fadb8ffc
$ docker run -d --name nginx2 -p 8081:80 nginx
a4d7a79833a558a1dc619019b77938999557ef858ecc84b8c83844a22137fa56
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a4d7a79833a5 nginx "/docker-entrypoint.…" 4 seconds ago Up 2 seconds 0.0.0.0:8081->80/tcp, :::8081->80/tcp nginx2
d0cdb3f0af4f nginx "/docker-entrypoint.…" 13 seconds ago Up 12 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp nginx1
- 查看网络设备
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:16:3d:ab brd ff:ff:ff:ff:ff:ff
altname enp0s5
altname ens5
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:7e:92:97:c9 brd ff:ff:ff:ff:ff:ff
30: vetha9d0324@if29: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ba:0f:72:b2:48:12 brd ff:ff:ff:ff:ff:ff link-netnsid 0
32: veth11ff0d5@if31: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 3a:2c:d0:46:01:24 brd ff:ff:ff:ff:ff:ff link-netnsid 1
$ ip link show master docker0
30: vetha9d0324@if29: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ba:0f:72:b2:48:12 brd ff:ff:ff:ff:ff:ff link-netnsid 0
32: veth11ff0d5@if31: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 3a:2c:d0:46:01:24 brd ff:ff:ff:ff:ff:ff link-netnsid 1
可以看到多了 30: vetha9d0324@if29 和 32: veth11ff0d5@if31 两个 veth 设备,并且都连到了 docker0 网桥。以第一个为例,其意思是编号为 30 的 veth 设备,与之配对的是 @if29,即编号为 29 的 veth,而这个设备应该是在容器内部的,我们进入对应容器查看一下。
$ docker run -it --net container:d0cdb3f0af4f nicolaka/netshoot
dP dP dP
88 88 88
88d888b. .d8888b. d8888P .d8888b. 88d888b. .d8888b. .d8888b. d8888P
88' `88 88ooood8 88 Y8ooooo. 88' `88 88' `88 88' `88 88
88 88 88. ... 88 88 88 88 88. .88 88. .88 88
dP dP `88888P' dP `88888P' dP dP `88888P' `88888P' dP
Welcome to Netshoot! (github.com/nicolaka/netshoot)
Version: 0.13
d0cdb3f0af4f ~ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
d0cdb3f0af4f ~ cat /sys/class/net/eth0/iflink
30
可以看到容器内部的 eth0 设备为 29: eth0@if30,其编号为 29,关联的设备编号是 30。此时整个网络结构如图:
知道了容器内网的网络情况,我们在看下数据是怎样传输的。首先看下容器内部的路由表信息
d0cdb3f0af4f ~ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.18.0.1 0.0.0.0 UG 0 0 0 eth0
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
所有请求 172.1.0.0/16 网段的都会走 eth0 网卡,我们知道这个网卡是与 docker0 相连的,因此网络包会被发送给 docker0 网桥,最终由网桥进行地址转发,将网络包发送给对应的容器或者主机。
我们在来看下主机的路由表:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.159.253 0.0.0.0 UG 100 0 0 eth0
100.100.2.136 172.17.159.253 255.255.255.255 UGH 100 0 0 eth0
100.100.2.138 172.17.159.253 255.255.255.255 UGH 100 0 0 eth0
172.17.144.0 0.0.0.0 255.255.240.0 U 100 0 0 eth0
172.17.159.253 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
可以看到请求 172.18.0.0/16 网段的都会路由至 docker0 设备,最终发送到某个容器,因此我们在主机访问刚创建的 NGINX 容器是可以访问成功的。
$ curl 172.18.0.2
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
. . .
容器的网络 namespace 是互相隔离的,上述容器创建的过程基本可以概括为:
- 创建 namespace
- 创建 veth 对并设置地址
- 将 veth 对一头连到容器的 namespace,一头连到docker0
- 启动 veth 设备,初始化路由表
我们完全可以通过命令行模拟上述操作,实现两个网络 namespace 的互通,步骤如下:
1. 创建 namespace
$ sudo ip netns add test1
$ sudo ip netns add test2
2. 创建 veth 对
$ sudo ip link add veth-test1 type veth peer name veth-test2
3. 将 veth 对加到 namespace 中
$ sudo ip link set veth-test1 netns test1
$ sudo ip link set veth-test2 netns test2
4. 给 veth 添加地址
$ sudo ip netns exec test1 ip addr add 192.168.1.1/24 dev veth-test1
$ sudo ip netns exec test2 ip addr add 192.168.1.2/24 dev veth-test2
5. 启动 veth 设备
$ sudo ip netns exec test1 ip link set dev veth-test1 up
$ sudo ip netns exec test2 ip link set dev veth-test2 up
6. 在 test1 namespace 中访问 test2
$ sudo ip netns exec test1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.060 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.053 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.038 ms
CNI 规范
鉴于网络通信的复杂性与专业性,Kubernetes 本身并没有提供网络相关的功能。业界的做法是将网络功能从容器运行时以及容器编排工具中剥离出去,形成容器网络标准,具体实现以插件的形式接入,从而具有更好的扩展性,
在早期 Docker 提出过 CNM 规范(Container Network Model,容器网络模型),但被后来 Kubernetes 提出的 CNI(Container Network Interface,容器网络接口)规范 代替,两者功能基本一致。CNI 主要定义了两种能力:
- 网络生命周期管理:主要负责网络的创建、删除等操作。
- IP 地址管理:主要包括 IP 地址的分配与回收,这里要求 Pod 的 IP 在集群内具有唯一性。
下面是 cni 定义的接口,可以看到操作类只有 Add 和 Del 两种方法。
type CNI interface {
AddNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) (types.Result, error)
CheckNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error
DelNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error
GetNetworkListCachedResult(net *NetworkConfigList, rt *RuntimeConf) (types.Result, error)
GetNetworkListCachedConfig(net *NetworkConfigList, rt *RuntimeConf) ([]byte, *RuntimeConf, error)
AddNetwork(ctx context.Context, net *PluginConfig, rt *RuntimeConf) (types.Result, error)
CheckNetwork(ctx context.Context, net *PluginConfig, rt *RuntimeConf) error
DelNetwork(ctx context.Context, net *PluginConfig, rt *RuntimeConf) error
GetNetworkCachedResult(net *PluginConfig, rt *RuntimeConf) (types.Result, error)
GetNetworkCachedConfig(net *PluginConfig, rt *RuntimeConf) ([]byte, *RuntimeConf, error)
ValidateNetworkList(ctx context.Context, net *NetworkConfigList) ([]string, error)
ValidateNetwork(ctx context.Context, net *PluginConfig) ([]string, error)
GCNetworkList(ctx context.Context, net *NetworkConfigList, args *GCArgs) error
GetStatusNetworkList(ctx context.Context, net *NetworkConfigList) error
GetCachedAttachments(containerID string) ([]*NetworkAttachment, error)
GetVersionInfo(ctx context.Context, pluginType string) (version.PluginInfo, error)
}
有了 CNI 规范,针对容器的网络操作就只需要面向 CNI 即可,在创建 Pod 时,由由容器运行时访问 CNI 接口,最终由网络插件完成 Pod 网络环境的设置,而 Kubernetes 不关心具体的实现细节。大致工作流程如下:
- 所有可用的插件全部位于
/opt/cni/bin目录。
$ ls /opt/cni/bin/
bandwidth calico dhcp firewall host-device ipvlan macvlan ptp static tuning vrf
bridge calico-ipam dummy flannel host-local loopback portmap sbr tap vlan
- 被选定的 CNI 插件会在
/etc/cni/net.d/目录下创建配置文件,以 flannel 为例配置如下:
{
"cniVersion": "0.3.1",
"name": "container-cni-list",
"plugins": [
{
"type": "flannel",
"delegate": {
"isDefaultGateway": true,
"hairpinMode": true,
"ipMasq": true,
"kubeconfig": "/etc/cni/net.d/flannel-kubeconfig"
}
}
]
}
容器运行时基于上述配置将列表的第一个插件选择为默认插件。
kubelet 给予 CRI 接口调用容器运行时创建 Pod。
容器运行时负责创建网络 namespace,并调用 CNI 为 Pod 分配网络。
CNI 配置完成后将 IP 地址等信息返回给容器运行时,在由 kubelet 更新到 Pod 的状态字段中,完成网络配置。
通过 CNI 这种开放性设计,Kubernetes 不需要在关心复杂的网络实现,转而交给社区去实现,从而打造出了丰富的 Kubernetes 网络插件形态。下面是一些常见的 CNI 插件:

跨主机的网络通信
Docker 是单机的,而 Kubernetes 通常是多节点的集群,因此不同节点的 Pod 需要进行跨主机的网络通信。跨主机的网络通信方案目前主要有三种方式:
Overlay 模式
在基础物理网络之上,在虚拟化一层网络来进行网络通信。像 Flannel 的 VXLAN 、Calico 的 IPIP 模式、Weave 等 CNI 插件都采用的了该模式。
路由模式
该模式下跨主机的网络通信是直接通过宿主机的路由转发实现的,和 Overlay 相比其优势在于无需额外的封包解包,性能会有所提升,但坏处是路由转发依赖网络底层环境的支持,要么支持二层连通,要么支持 BGP 协议实现三层互通。Flannel 的 HostGateway 模式、Calico 的 BGP 模式都是该模式的代表。
Underlay 模式
容器直接使用宿主机网络通信,直接依赖于虚拟化设备和底层网络设施,上面的路由模式也算是 Underlay 模式的一种。理论上该模式是性能最好的,但因为必须依赖底层,并且可能需要特定的软硬件部署,无法做到 Overlay 那样的自由灵活的使用。
Pod To Pod
下面以 Flannel 插件的实现为例看下最常见的 Overlay 和路由模式的具体实现。
注意:Flannel 插件的更新已经停止,实际生产中已经不再建议使用。这里只是为了方便理解选择了相对直观的 Flannel 插件做学习。
Flannel UDP
Flannel 是 CoreOS 为 Kubernetes 设计的配置三层网络(IP层)的开源解决方案。其构建 Overlay 网络有两种模式:UDP 和 VXLAN。我们首先看下 UDP 模式。
Flannel 会创建名为 kube-flannel 的 DaemonSet 对象,从而在每个节点上创建 Pod 运行 flanneld 程序。另外 Flannel 还会创建名为 flannel.0 的虚拟网络设备,在主机网络上创建另外一层扁平的 Overlay 网络。
在 Overlay 网络中,每个 Pod 都有唯一的 IP,Pod 之间可以直接使用 IP 地址和其他节点的 Pod 通信。另外 Kubernetes 会在每个节点上创建一个 cni0 bridge 来实现本机容器的通讯,通信过程和我们上面提到的容器间的网络通信基本一致,这里我们只关注跨节点的网络通信。
首先看一下集群内节点和 Pod 的 IP 地址:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node1 Ready control-plane 24h v1.30.4 172.19.0.8 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
node2 Ready control-plane 24h v1.30.4 172.19.0.13 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
node3 Ready <none> 24h v1.30.4 172.19.0.15 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-576c6b7b6-6rdhf 1/1 Running 0 24h 10.233.66.2 node3 <none> <none>
nginx-deployment-576c6b7b6-jdt7x 1/1 Running 0 24h 10.233.64.4 node1 <none> <none>
nginx-deployment-576c6b7b6-rrgtc 1/1 Running 0 24h 10.233.65.3 node2 <none> <none>
查看三个节点的 IP 信息,可以看到每个节点都有 flannel.0 设备,IP 依次是 10.233.64.0/32、10.233.65.0/32、10.233.66.0/32。
$ node1
11: flannel0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether 02:df:3d:63:5f:1c brd ff:ff:ff:ff:ff:ff
inet 10.233.64.0/32 scope global flannel0
$ node2
11: flannel.0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether 02:df:3d:63:5f:1c brd ff:ff:ff:ff:ff:ff
inet 10.233.65.0/32 scope global flannel.0
$ node3
11: flannel.0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether 02:df:3d:63:5f:1c brd ff:ff:ff:ff:ff:ff
inet 10.233.66.0/32 scope global flannel.0
我们在查看下 node1 节点上的路由表:
$ ip route
default via 172.19.0.1 dev eth0 proto dhcp src 172.19.0.8 metric 100
10.233.64.0/24 dev cni0 proto kernel scope link src 10.233.64.1
10.233.65.0/24 via 10.233.65.0 dev flannel.0 onlink
10.233.66.0/24 via 10.233.66.0 dev flannel.0 onlink
可以看到如果是发送给 10.233.64.0/24 即 node1 的 Pod 的 IP 地址,则直接通过 cni0 设备发送,如果是 10.233.65.0/24 和 10.233.66.0/24 也就是访问 node2、node3 的 Pod ,则通过 flannel.0 设备发送,下面是整体通信流程:
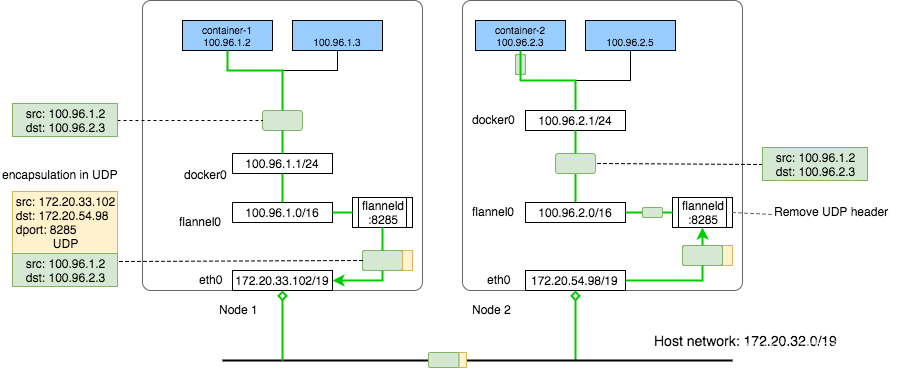
- 创建原始 IP 包,源地址为 node1 中 Pod IP,目的地址为 node2 中 Pod IP。
- 数据包通过 veth 设备从 node1 的 Pod 发送到 cni0 bridge。
- cni0 bridge 将数据包发送到 flannel.0 设备(根据主机路由表判断)。
- 发给 flannel.0 的包会由 flanneld 程序处理,它会将 IP 包作为数据打包到 UDP 包中,并在 etcd 中找到目标 Pod 所在节点的 IP 地址(即 Node2 的 IP 地址),最终封装为完整的 IP 包进行发送。
- Node2 收到 IP 包后进行逆向操作,先将数据报发送给 flanneld 程序,解包后经 flannel.1、cni0 bridge 最终发送到容器。
在 UDP 模式下,flanneld 程序需要将数据包打包到 UDP 包中,然后发送给目标节点,目标节点再进行解包,可以看到每次打包都需要 3 次内核态和用户态的转换,因此 UDP 模式下性能较低,已经不再推荐使用。
Flannel VXLAN
Flannel 默认采用 VXLAN 模式,通过 VXLAN 在主机之间建立逻辑隧道,并且直接在内核打包,从而提升性能。在 VXLAN 模式下,每个节点都会创建一个 VTEP 设备,可以通过 ip link show type vxlan 查看。执行命令后可以看到,我们的三个节点每个节点都有 flannel.1 的 vxlan 设备,端口为 8472,VNI 为 1。
$ node1 > ip -d addr show type vxlan
11: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether 02:df:3d:63:5f:1c brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 1 local 172.19.0.8 dev eth0 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 10.233.64.0/32 scope global flannel.1
$ node2 > ip -d addr show type vxlan
10: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether aa:4d:1c:d6:b1:4a brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 1 local 172.19.0.13 dev eth0 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 10.233.65.0/32 scope global flannel.1
$ node3 > ip -d addr show type vxlan
10: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8450 qdisc noqueue state UNKNOWN group default
link/ether 3a:71:37:9f:0f:b9 brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan id 1 local 172.19.0.15 dev eth0 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 10.233.66.0/32 scope global flannel.1
Flannel 在 VXLAN 模式下的数据传输过程如下:
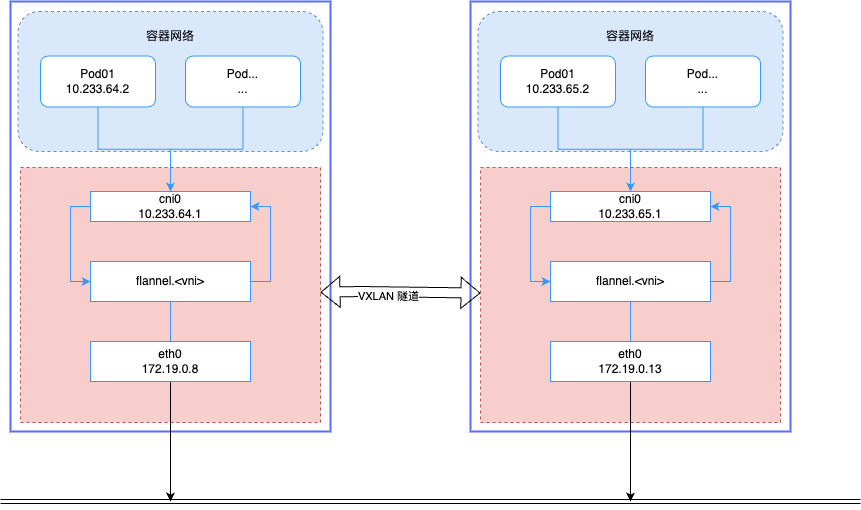
- Pod 发送请求,IP 包的源地址和目的地址是源 Pod IP 和目的 Pod IP。
- 数据报经由 cni0 bridge 传输到 flannel.1 设备进行 VXLAN 封包,然后作为 UDP 包发出。
- node1 将 UDP 包发送到 node2
- node2 收到 UDP 包后,flannel.1 设备接收进行解包,获取内部的数据包。
- 数据包发送到 cni0 bridge 设备,然后转发到目标 Pod。
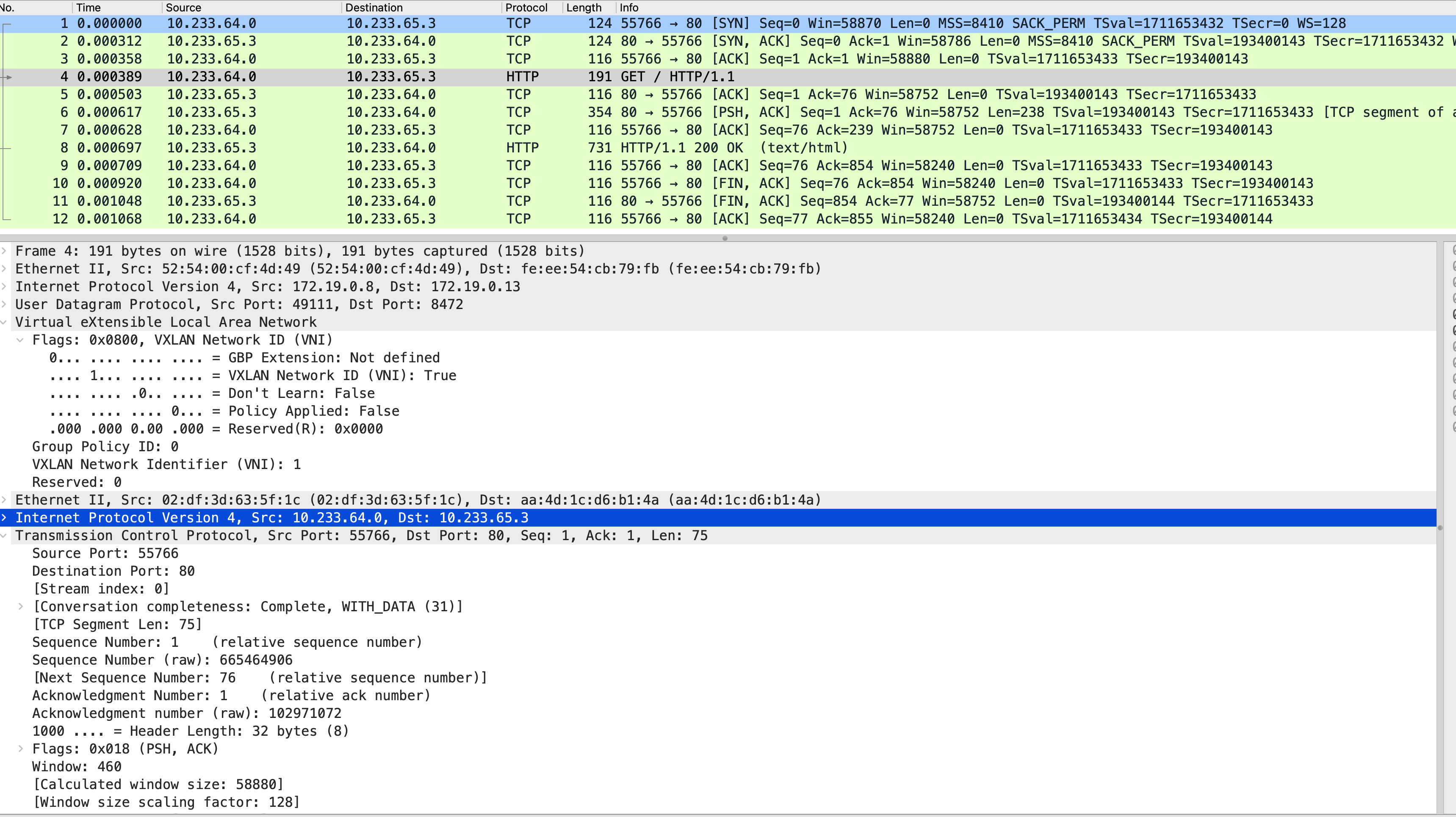
我们用 tcpdump 抓包后用 wireshark 打开看下 UDP 包中 VXLAN 的信息如下:
- 外层包目的地址是 node2 的 IP 地址:172.19.0.13。
- 外层包目的端口为 8472,对应 flannel.1 的端口
- VNI 为 1,表示 flannel.1 对应的 VNI
- VXLAN 内部封装的 IP 包源地址和目的地址就是源 Pod 和目标 Pod 的 IP 地址。
Flannel host-gw
Flannel 的 host-gw 模式是基于路由的网络方案,和 VXLAN 模式不同,host-gw 模式下,Flannel 会直接将数据包发送给目标节点,无需经过中间的 VXLAN 隧道。可以通过修改其配置设置为 host-gw 来设置。
net-conf.json:
----
{
"Network": "10.233.64.0/18",
"EnableIPv4": true,
"Backend": {
"Type": "host-gw"
}
}
在 host-gw 模式下,当 Pod 创建并分配 IP 时,Flannel 会在主机创建路由规则,Pod 之间的通信是通过 IP 路由实现的。我们在创建一个三实例的 Nginx Deployment 并查看主机的路由规则。
$ ip link show type vxlan
$ ip -d addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
inet 127.0.0.1/8 scope host lo
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc mq state UP group default qlen 1000
inet 172.19.0.8/20 metric 100 brd 172.19.15.255 scope global eth0
23: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc noqueue state UP group default qlen 1000
inet 10.233.64.1/24 brd 10.233.64.255 scope global cni0
valid_lft forever preferred_lft forever
24: veth36c11991@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc noqueue master cni0 state UP group default
25: vethf7cb8841@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc noqueue master cni0 state UP group default
26: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
27: vethadfffbd3@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc noqueue master cni0 state UP group default
$ ip -d route
unicast default via 172.19.0.1 dev eth0 proto dhcp scope global src 172.19.0.8 metric 100
unicast 10.233.64.0/24 dev cni0 proto kernel scope link src 10.233.64.1
unicast 10.233.65.0/24 via 172.19.0.13 dev eth0 proto boot scope global
unicast 10.233.66.0/24 via 172.19.0.15 dev eth0 proto boot scope global
unicast 172.19.0.0/20 dev eth0 proto kernel scope link src 172.19.0.8 metric 100
unicast 172.19.0.1 dev eth0 proto dhcp scope link src 172.19.0.8 metric 100
unicast 183.60.82.98 via 172.19.0.1 dev eth0 proto dhcp scope global src 172.19.0.8 metric 100
unicast 183.60.83.19 via 172.19.0.1 dev eth0 proto dhcp scope global src 172.19.0.8 metric 100
可以看到主机上没有创建 vxlan 设备,而是建好了 3 条路由规则:
$ ip -d route
unicast 10.233.64.0/24 via 172.19.0.8 dev eth0 proto boot scope global
unicast 10.233.65.0/24 dev cni0 proto kernel scope link src 10.233.65.1
unicast 10.233.66.0/24 via 172.19.0.15 dev eth0 proto boot scope global
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node1 Ready control-plane 12m v1.30.4 172.19.0.8 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
node2 Ready control-plane 12m v1.30.4 172.19.0.13 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
node3 Ready <none> 11m v1.30.4 172.19.0.15 <none> Ubuntu 22.04 LTS 5.15.0-124-generic containerd://1.7.23
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-576c6b7b6-8snps 1/1 Running 0 104s 10.233.65.3 node2 <none> <none>
nginx-deployment-576c6b7b6-8t282 1/1 Running 0 104s 10.233.66.2 node3 <none> <none>
nginx-deployment-576c6b7b6-ttn9g 1/1 Running 0 104s 10.233.64.4 node1 <none> <none>
我们以 node02 节点看到的 unicast 10.233.64.0/24 via 172.19.0.8 dev eth0 proto boot scope global 这条规则为例,其含义是对 10.233.64.0/24 网段的数据包,通过 eth0 网卡,发往 172.19.0.8 这个 IP 地址。
因此如果我们访问位于 Node01 的 nginx-deployment-576c6b7b6-ttn9g(IP:10.233.64.4),那么数据包会通过 eth0 网卡,发往 172.19.0.8 这个 IP 地址,然后通过 172.19.0.8 这个 IP 地址,发往 10.233.64.4 这个 IP 地址。
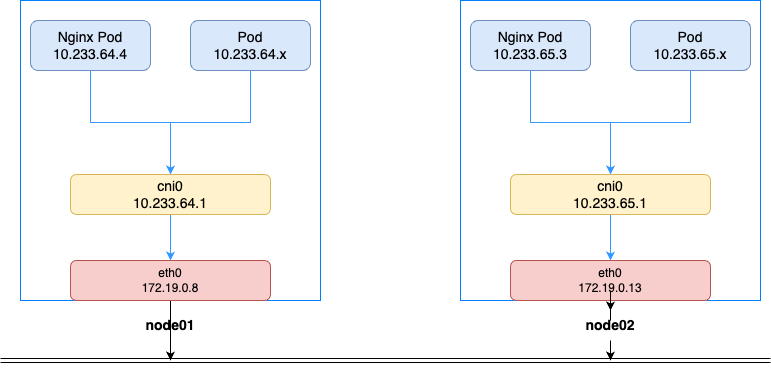
host-gw 有几个特点:
省去了 overlay 网络的封包解包过程,性能上会有所提升。host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN 隧道机制的网络方案,性能损失在 20%~30% 左右。
通过路由规则可以看到,当在 node02 访问 node01 的 Pod 时,数据包是直接路由到了 node01,node02 需要通过 ARP 协议获取 node01 的 Mac 地址后发送数据包,因此 node02 需要和 node01 二层互通。也就是说 host-gw 模式下,K8s 集群节点必须都是二层互通的。
Calico BGP 模式
Service To Pod
Service 简介
Kuberetes 通过抽象的 Service 来组织对集群内 pod 的访问,因为 pod 是可以被动态创建和销毁的,其 IP 地址也会随之变化,所以需要一个抽象的资源来做稳定的服务发现和负载均衡,Service 就是这样一个资源对象。Service 通过 Label Selector 来选定一组 Pod,然后为这组 Pod 提供一个稳定的访问入口。
我们使用如下 yaml 文件创建一个有 3 个副本的 nginx deployment 并创建 Service。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # 创建 3 个 Pod
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest # 使用最新的 NGINX 镜像
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
app: nginx
spec:
type: ClusterIP # 服务类型为 ClusterIP
selector:
app: nginx
ports:
- protocol: TCP
port: 80 # Service 的端口
targetPort: 80 # Pod 内容器的端口
虽然 Service 是对 Pod 的代理和负载均衡,但 Service 和 Pod 并不直接发生关联,而是通过 Endpoints 对象关联。处于 Running 状态,并且通过 readinessProbe 检查的 Pod 会出现在 Service 的 Endpoints 列表里,当某一个 Pod 出现问题时,Kubernetes 会自动把它从 Endpoints 列表里摘除掉。
在早期版本中, Service 只会包含一个 Endpoints 对象,当 Pod 的 IP 发生变化时,Endpoints 对象的 IP 也会随之变化,但这样可能会导致 Endpoints 对象的 IP 列表频繁变化,比如某个 Pod 有 3000 个副本需要滚动升级,这样会导致 Endpoints 至少变动 3000 次,同时也会导致 iptables 规则频繁更新,从而导致性能问题。
为了解决这个问题,Kubernetes 在 1.14 版本引入了 EndpointSlice 并在 1.19 版本默认启用,其思路非常简单:将一个 Endpoints 对象分成多个 EndpointSlice 对象。每次变更只更新部分 EndpointSlice 对象,从而减少 Endpoints 对象的变动。
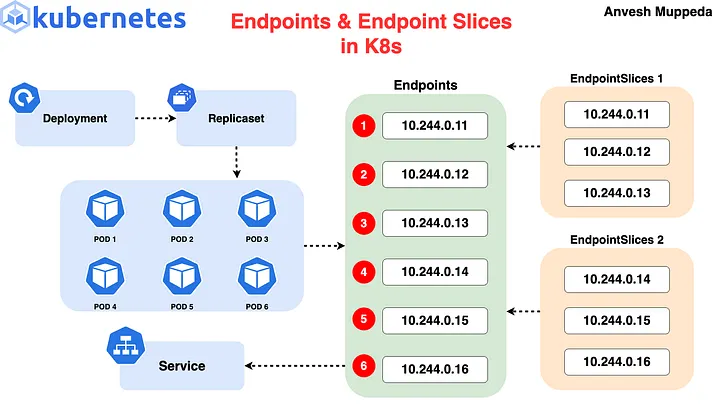
图片来自:A Hands-On Guide to Kubernetes Endpoints & EndpointSlices
下面是使用上述 yaml 创建的 nginx 的 Pod、Service、Endpoints 对象,可以看到有一个和 Service 同名的 Endpoints 对象,包含了3 个 Pod 的 IP。
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 44h
nginx-service ClusterIP 10.233.32.140 <none> 80/TCP 24h
$ kubectl get endpoints
NAME ENDPOINTS AGE
nginx-service 10.233.102.131:80,10.233.71.2:80,10.233.75.2:80 24h
$ kubectl get endpointslices
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
nginx-service-zsrzj IPv4 80 10.233.102.131,10.233.75.2,10.233.71.2 25h
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-54b9c68f67-cfpgf 1/1 Running 0 24h 10.233.75.2 node2 <none> <none>
nginx-deployment-54b9c68f67-kldjf 1/1 Running 0 24h 10.233.71.2 node3 <none> <none>
nginx-deployment-54b9c68f67-q4ggs 1/1 Running 0 24h 10.233.102.131 node1 <none> <none>
Service 是通过 Label Selector 来选定要代理的 Pod 的,但其可以分为有 Label Selector 和没有 Label Selector 的Service, 两者的差别在于:
有
Label Selector的 Service 用来代理一组 Pod,主要是为集群内 Pod 提供服务发现、负载均衡。没有
Label Selector的 Service 通常用来代理集群外部的服务,主要应用于如下的场景:- 访问的 Service 在生产中是一个集群外服务,比如云数据库。服务不在集群内但是需要通过集群内部访问。
- 所访问的服务不在同一个命名空间。
- 正在迁移服务到 Kubernetes,并只有部分backend服务移到K8s中。
因为 Service 是基于通过 Endpoints 进行代理,所以 Endpoints 内的 IP 地址并不一定都是 Pod 的 IP,完全可以是 K8s 集群外的服务。比如我们的 ElasticSearch 集群是部署在主机上的,可以通过下面的方式创建 Service,这样在应用内部就可以配置固定域名来对 ElasticSearch 进行访问,如果 ElasticSearch 服务的 IP 发生变化,只需要修改 EndPoints 即可无需修改应用配置。
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: default
spec:
ports:
- port: 9200
protocol: TCP
targetPort: 9200
---
apiVersion: v1
kind: Endpoints
metadata:
name: elasticsearch
namespace: default
subsets:
- addresses:
- ip: 192.168.24.14
- ip: 192.168.24.15
- ip: 192.168.24.16
ports:
- port: 9200
Service 分类
Service 主要有下面 5 种类型(ServiceType):
5.2.1 ClusterIP
这是 Service 的默认模式,使用集群内部 IP 进行 Pod 的访问,对集群外不可见。ClusterIP 其实是一条 iptables 规则,不是一个真实的 IP,不能被路由到。kubernetes通过 iptables 把对 ClusterIP:Port 的访问重定向到 kube-proxy 或者具体的 pod 上。
5.2.2 NodePort
NodePort 与 Cluster IP不一样的是,它会集群中的每个节点开一个稳定的端口(范围 30000 - 32767 )给外部访问。
当 Service 以 NodePort 的方式 expose 的时候,此时该服务会有三个端口:port,targetPort,nodePort。
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
selector:
app: hello-world
ports:
- protocol: TCP
port: 8080
targetPort: 80
nodePort: 30036
- nodePort: 30036 是搭配 NodeIP 提供给集群外部访问的端口。
- port:8080 是集群内访问该服务的端口。
- targetPort:80 是Pod 内容器服务监听的端口。
5.2.3 LoadBalancer
负载均衡器,一般都是在使用云厂商提供的 Kubernetes 服务时,使用各种云厂商提供的负载均衡能力,使我们的服务能在集群外被访问。
如果是自己部署的集群,Kubernetes 本身没有提供类似功能,可以使用 MetalLB 来部署。
5.2.4 ExternalName Service
ExternalName Service 用来映射集群外服务的 DNS,意思是这个服务不在 Kubernetes 里,但是可以由 Kubernetes 的 Service 进行转发。
比如:我们有一个AWS RDS 的服务,其地址是 test.database.aws-cn-northeast1b.com,但为了屏蔽细节以及为了方便日后的迁移,但我们应用内配置的 URL 是 db-service。这时就可以创建一个名为 db-service 的 ExternalName Service 将其映射到外部的 DNS 地址。集群内的 pod 访问 db-service 时,Kubernetes DNS 服务器将返回带有 CNAME 记录的 test.database.aws-cn-norheast1b.com。
apiVersion: v1
kind: Service
metadata:
name: db-service
spec:
type: ExternalName
externalName: test.database.aws-cn-northeast1b.com
ports:
- port: 80
5.2.5 Headless Service
有时候如果我们不需要 Service 作为负载均衡转发请求,我们可以把 ClusterIP 设置成 None,从而创建一个 HeadlessService。示例如下:
apiVersion: v1
kind: Service
metadata:
name: nginx-headless
spec:
clusterIP: None
ports:
- port: 80
selector:
app: nginx
下面是相关信息
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-headless ClusterIP None <none> 80/TCP 3s
# ubuntu @ node1 in ~/kubespec [13:54:58]
$ kubectl get endpoints
NAME ENDPOINTS AGE
nginx-headless 10.233.102.131:80,10.233.71.2:80,10.233.75.2:80 13s
可以看到 Headless Service 自身没有 IP 地址,当 Pod 通过该服务访问时,不会走 kube-proxy 将请求转发到某个 Pod 或外部节点,而是其会返会 Endpoints 列表里的 IP 地址,Pod 拿到 IP 自行决定去访问哪些地址。 在部署有状态应用经常会用到 HeadlessService 以减少节点之间的通信时间。
这里我们只是简单介绍 Service 的相关定义,更多的使用还请参考官方文档,我们重点来看下 Service 的请求转发是如何实现的。
kube-proxy 实现原理
Service 相关的请求转发是由 kube-proxy 组件实现的,每个节点上都会运行该组件。kube-proxy 会监听集群中 Service 和 Endpoints 的变化,并基于此更新每台节点的 iptables 或 ipvs 等规则,从而完成请求的转发。鉴于篇幅原因,我们这里只对最常用的 ClusterIP 类型的 Service 做介绍。
kube-proxy 的代理模式有下面几种:
- UserSpace 模式(已废弃)
- iptables 模式(默认)
- ipvs 模式
- nftables 模式(实验性)
我们来分别看下这几种模式的工作原理。
UserSpace 模式
这是早期使用的一种模式。该模式下,对 Service 的访问会通过 iptables 转到 kube-proxy 程序,再由 kube-proxy 程序转发到对应的 Pod 中。
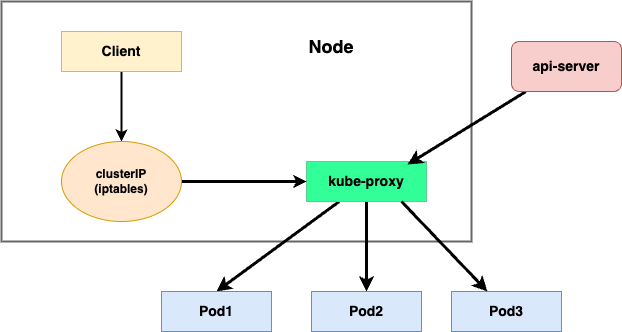
这种模式的转发是在用户空间的 kube-proxy 程序中进行到,涉及到用户态和内核态的转换,性能较低,已经不再使用。
iptables 模式
该模式下,kube-proxy 仅负责设置 iptables 转发规则,对于 Service 的访问通过 iptables 规则做 NAT 地址转换,最终随机访问到某个 Pod。该方式避免了用户态到内核态的转换,提升了性能和可靠性。
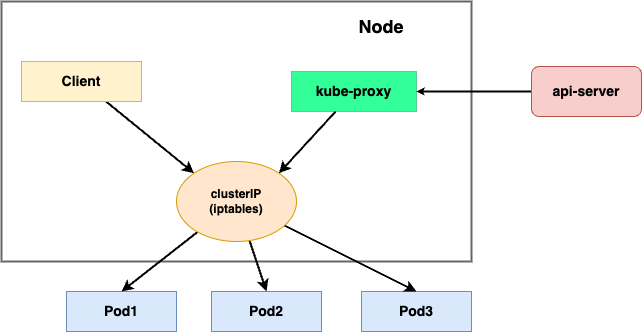
需要注意的是,kube-proxy 在 iptables 模式下运行时,如果所选的第一个 Pod 没有响应, 则连接失败。
这与 userspace 模式不同,在 userspace 模式下,kube-proxy 如果检测到第一个 Pod 连接失败,其会自动选择其他 Pod 重试。
可以通过设置 readiness 就绪探针,保证只有正常使用 Pod 可以作为 endpoint 使用,保证 iptables 模式下的 kube-proxy 能访问的都是正常的 Pod,避免将流量通过 kube-proxy 发送到已经发生故障的 Pod 中。
我们设置 kube-proxy 的 mode 为 iptables 后看下是如何工作的。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: kube-proxy
name: kube-proxy
namespace: kube-system
data:
config.conf: |-
. . .
mode: iptables
. . .
首先创建一个 Service 代理三个 Nginx Pod。
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service ClusterIP 10.233.40.88 <none> 80/TCP 98s
$ kubectl get endpoints
NAME ENDPOINTS AGE
nginx-service 10.233.64.4:80,10.233.65.3:80,10.233.66.2:80 102s
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-576c6b7b6-6rdhf 1/1 Running 0 107s 10.233.66.2 node3 <none> <none>
nginx-deployment-576c6b7b6-jdt7x 1/1 Running 0 107s 10.233.64.4 node1 <none> <none>
nginx-deployment-576c6b7b6-rrgtc 1/1 Running 0 107s 10.233.65.3 node2 <none> <none>
创建完成后我们看下主机上的 iptables 规则,不妨回忆下数据包在 netfilter 中 HOOK 点:
- 本机 or Kubernetes 集群内访问 Service,需要经过 netfilter 的 OUTPUT 点
- 集群外访问 Service,需要经过 netfilter 的 PREROUTING 点
因此 iptables 需要在上述两个点设置规则,将 Service 的 ClusterIP 进转换为 Pod IP ,需要在 nat 表的 PREROUTING 和 OUTPUT 链上设置规则。
我们来验证下,首先找下 PREROUTING 和 OUTPUT 链上有没有挂载 Service 的规则,我们可以找到如下两条规则:
# 查看 NAT 表的规则
$ sudo iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
6173 330K KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
12764 792K KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
两条规则的 source 和 destination 都是 0.0.0.0/0,target 都是 KUBE-SERVICES,表示所有发往本机的包和集群外发往本机的包都会转到 KUBE-SERVICES 链上。
接下来我们在看下 KUBE-SERVICES 链的规则。
$ sudo iptables -t nat -nvL KUBE-SERVICES | column -t
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
# 将目标地址为 10.233.40.88(nginx-service 的 ClusterIP) 的包转到 KUBE-SVC-V2OKYYMBY3REGZOG 链
0 0 KUBE-SVC-V2OKYYMBY3REGZOG tcp -- * * 0.0.0.0/0 10.233.40.88 /* default/nginx-service cluster IP */
0 0 KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- * * 0.0.0.0/0 10.233.0.1 /* default/kubernetes:https cluster IP */
0 0 KUBE-SVC-ZRLRAB2E5DTUX37C udp -- * * 0.0.0.0/0 10.233.0.3 /* kube-system/coredns:dns cluster IP */
0 0 KUBE-SVC-FAITROITGXHS3QVF tcp -- * * 0.0.0.0/0 10.233.0.3 /* kube-system/coredns:dns-tcp cluster IP */
0 0 KUBE-SVC-QKJQYQZXY3DRLPVB tcp -- * * 0.0.0.0/0 10.233.0.3 /* kube-system/coredns:metrics cluster IP */
8893 493K KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
可以看到第一条 default/nginx-service 的规则,这个对应到我们的刚创建的 nginx-service ,其 target 是 KUBE-SVC-V2OKYYMBY3REGZOG,因此该包会转到 KUBE-SVC-V2OKYYMBY3REGZOG 链上。继续查看 KUBE-SVC-V2OKYYMBY3REGZOG 链的规则。
$ sudo iptables -t nat -nvL KUBE-SVC-V2OKYYMBY3REGZOG | column -t
Chain KUBE-SVC-V2OKYYMBY3REGZOG (1 references)
pkts bytes target prot opt in out source destination
# 对集群外的包标记设置为 0x4000
0 0 KUBE-MARK-MASQ tcp -- * * !10.233.64.0/18 10.233.40.88 /* default/nginx-service cluster IP */
# 将发到该链的包随机转发到三个链中,iptables 规则是从上到下逐条匹配,因此要设置匹配概率保证每条的匹配规则相同,下面一次是 1/3,1/2 , 1。
0 0 KUBE-SEP-FOSYNTRPSERVNODE all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-service -> 10.233.64.4:80 */ statistic mode random probability 0.33333333349
0 0 KUBE-SEP-2H4DDHMGXF2HFD2H all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-service -> 10.233.65.3:80 */ statistic mode random probability 0.50000000000
0 0 KUBE-SEP-76F2POANROK2TCTZ all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-service -> 10.233.66.2:80 */
可以看到有 3 条规则的注释是带 IP 的,表示将包转发到 PodIP:80,其对应三条 KUBE-SEP- 开头的链,与此同时,其匹配的概率从上到下分别是 0.333,0.5 和 1,这是因为 iptables 规则是从上到下逐条匹配,为了保证每条规则被匹配到的概率一致,因此其概率分别是 1/3,1/2 , 1。
我们选择其中一条 KUBE-SEP-2H4DDHMGXF2HFD2H 链,查看其规则。
$ sudo iptables -t nat -nvL KUBE-SEP-2H4DDHMGXF2HFD2H | column -t
Chain KUBE-SEP-2H4DDHMGXF2HFD2H (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.233.65.3 0.0.0.0/0 /* default/nginx-service */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-service */ tcp to:10.233.65.3:80
可以看到该链的 target 是 DNAT,表示将包的目的地址转换为 10.233.65.3:80,也就是 PodIP 地址和端口。最终,网络包的 destination 是 Pod 的 IP 地址和端口,从而完成请求的转发。
除了 3 条负责转发到 Pod 的规则,KUBE-SVC-V2OKYYMBY3REGZOG 下还有一条 target 为 KUBE-MARK-MASQ 的规则:
$ sudo iptables -t nat -nvL KUBE-SVC-V2OKYYMBY3REGZOG | column -t
Chain KUBE-SVC-V2OKYYMBY3REGZOG (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ tcp -- * * !10.233.64.0/18 10.233.40.88 /* default/nginx-service cluster IP */
$ sudo iptables -t nat -nvL KUBE-MARK-MASQ | column -t
Chain KUBE-MARK-MASQ (16 references)
pkts bytes target prot opt in out source destination
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
可以看到规则匹配的 source 是 !10.233.64.0/18,表示匹配的源地址不是 10.233.64.0/18 的地址,也就是非集群内的地址。这条规则表示来自集群外的请求,并且目标 IP 是 nginx-service 的 ClusterIP 的包会转发到 KUBE-MARK-MASQ 链上,然后该链的 target 是 MARK,表示将包的标记设置为 0x4000,被标记的包后续会由 KUBE-POSTROUTING 链做 SNAT 处理,处理方式是将响应包的源地址(Pod IP)转换为主机 的 IP 地址,然后主机将响应包发送到请求的客户端。
$ sudo iptables -t nat -nvL KUBE-POSTROUTING | column -t
Chain KUBE-POSTROUTING (1 references)
pkts bytes target prot opt in out source destination
14055 859K RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK xor 0x4000
0 0 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ random-fully
从上面的转发规则可以看出,Service 的 ClusterIP 本质上是 iptables 规则中的一个 IP ,在 Node 中是没有对应的网络设备的,因此在 Node 上 ping 该 IP 是 ping 不通的。
ipvs 模式
根据 K8s 官方博客 IPVS-Based In-Cluster Load Balancing Deep Dive 介绍,iptables 本质还是为了防火墙目的而设计的,其基于内核规则列表工作。这使得随着 K8s 集群的增大,kube-proxy 成为了集群扩展的瓶颈,随着节点、Pod、Service 增多,iptables 规则也越来越多,在做消息转发时的效率也就越低,因此又出现了 ipvs 模式来解决扩展性的问题。
ipvs 模式基于内核的 LVS(Linux Virtual Server)模块,最早在 1998 由章文嵩博士开发,并在 2004 年在 Linux 2.4 内核中被采纳。
LVS 也是基于 netfilter 框架,通过修改 MAC 层、IP 层、TCP 层的数据包,实现了交换机和网关的功能。
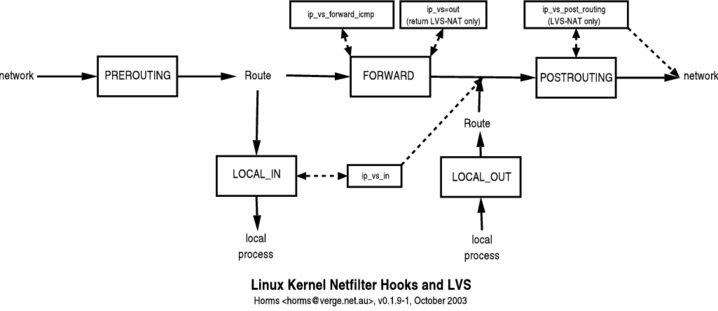
图片来自 LVS-HOWTO
关于 LVS 的更多细节可以参考相关文档,这里我们只关注 kube-proxy 的具体使用。
kube-proxy 会监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 默认采用轮询的方式将流量定向到后端Pod之一。
与 iptables 模式相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
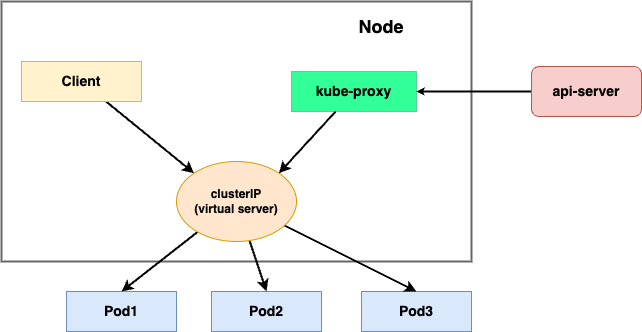
我们将 kube-proxy 配置为 ipvs 模式后看下具体的实现细节。
$ kubectl edit configmap kube-proxy -n kube-system
// change mode from "" to ipvs
mode: ipvs
还是以上面的 Service 为例,除了 nginx-service 这里还有 coredns 和 kubernetes 两个 Service。
$ kubectl get svc -o wide -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
default kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 18h <none>
default nginx-service ClusterIP 10.233.29.12 <none> 80/TCP 4m35s app=nginx
kube-system coredns ClusterIP 10.233.0.3 <none> 53/UDP,53/TCP,9153/TCP 18h k8s-app=kube-dns
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-576c6b7b6-jzkf9 1/1 Running 0 3m3s 10.233.75.2 node2 <none> <none>
nginx-deployment-576c6b7b6-mxvkl 1/1 Running 0 3m3s 10.233.71.2 node3 <none> <none>
nginx-deployment-576c6b7b6-xcxqx 1/1 Running 0 3m3s 10.233.102.131 node1 <none> <none>
IPVS & IPSet
在 IPVS 模式下,kube-proxy 会做下面一些事情:
- 创建一个虚拟网络设备 kube-ipvs0 ,所有 Service 的 IP 会加到该设备上。
- 创建 ipset,将 Service 的 IP 加到 ipset 中。
- 创建 iptables 规则,辅助流量转发。
ipset 会维护 3 个列表:
| set 名 | 成员信息 | 作用 |
|---|---|---|
| KUBE-CLUSTER-IP | ClusterIP 类型的 Service 的 ClusterIP + Port | |
| KUBE-NODE-PORT-TCP | NodePort 类型的 Service 指定的 TCP 端口 | |
| KUBE-NODE-PORT-UDP | NodePort 类型的 Service 指定的 UDP 端口 |
我们看下 node1 的虚拟网卡和 ipset 信息,可以看到上面的 3 个 Service 的 IP 都加到了 kube-ipvs0 设备上,ipset 中也有对应的 IP 和端口信息。
$ ip addr
28: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether ba:2c:1d:78:ae:f5 brd ff:ff:ff:ff:ff:ff
inet 10.233.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.233.0.3/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.233.29.12/32 scope global kube-ipvs0 # nginx-service 的 ClusterIP
valid_lft forever preferred_lft forever
$ sudo ipset list KUBE-CLUSTER-IP
Name: KUBE-CLUSTER-IP
Type: hash:ip,port
Revision: 6
Header: family inet hashsize 1024 maxelem 65536 bucketsize 12 initval 0x15dd7a3f
Size in memory: 488
References: 3
Number of entries: 6
Members:
10.233.29.12,tcp:80 # nginx-service 的 ClusterIP:Port
10.233.0.1,tcp:443
10.233.32.167,tcp:80
...
既然 Service 的 IP 都加到 kube-ipvs0 设备上,那么请求 Service IP 的包就会发到 kube-ipvs0 设备上,基于 IPVS 的规则进行转发。可以看到 nginx-service 的 IP 对应的 3 个 Pod 的 IP,其转发策略是 rr,即 Round Robin 轮询,因此请求会均匀的转发到 3 个 Pod 上。下面是对应的 ipvs 规则。
$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.233.29.12:80 rr # nginx-service 的 IP
# 3个 Pod 的 IP
-> 10.233.71.2:80 Masq 1 0 0
-> 10.233.75.2:80 Masq 1 0 0
-> 10.233.102.131:80 Masq 1 0 0
基于上述过程,我们发现在 IPVS 模式下好像不需要 iptables 的规则,那么 iptables 的规则是做什么用的呢?我们来看下,首先还是在 nat 表的 PREROUTING 和 OUTPUT 链上将所有请求转到 KUBE-SERVICES 链。
$ sudo iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
107K 5093K KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
296K 18M KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
然后在查看下 KUBE-SERVICES 链的规则:
$ sudo iptables -t nat -nvL KUBE-SERVICES | column -t
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
3 180 RETURN all -- * * 127.0.0.0/8 0.0.0.0/0
0 0 KUBE-MARK-MASQ all -- * * !10.233.64.0/18 0.0.0.0/0 /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst
57 3068 KUBE-NODE-PORT all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst
可以看到这里不再像 iptables 模式下那样有每个 Service 对应的规则,而是只有几条规则:
- 第一条:其匹配的源地址是 127.0.0.0/8,也就是本地的请求,target return 会直接返回到上一级链继续匹配。
- 第二条:对非集群内的包标记设置为
0x4000,被标记的包后续会由 KUBE-POSTROUTING 链做 SNAT 处理,处理方式是将响应包的源地址(Pod IP)转换为主机的 IP 地址,然后主机将响应包发送到请求的客户端。 - 第三条:表示将目标地址为本地的请求转发到 KUBE-NODE-PORT 链上。
- 第四条:match-set 的意思是匹配某个 ipset 集合,这里表示任意匹配了
KUBE-CLUSTER-IP的 set 的包,target 是 ACCEPT,表示允许转发。因此所有请求 Service 的包都会被放行。可以看到,IPVS 模式下,iptables 的规则只是用来标记和放行,不需要像 iptables 模式那样为每个 Service 创建规则并基于概率做负载均衡,真正的负载均衡是基于 IPVS 实现的。
和 iptables 模式下需要遍历规则相比,ipvs 直接使用哈希查找,时间复杂度有 O(N)变为 O(1),由此性能得到明显的提升。下图是 iptables 与 ipvs 模式的性能对比,可以看到在 10000 节点的集群上,ipvs 模式比 iptables 模式性能几乎高一倍。因此在大规模集群中一般都会推荐使用 IPVS 模式。 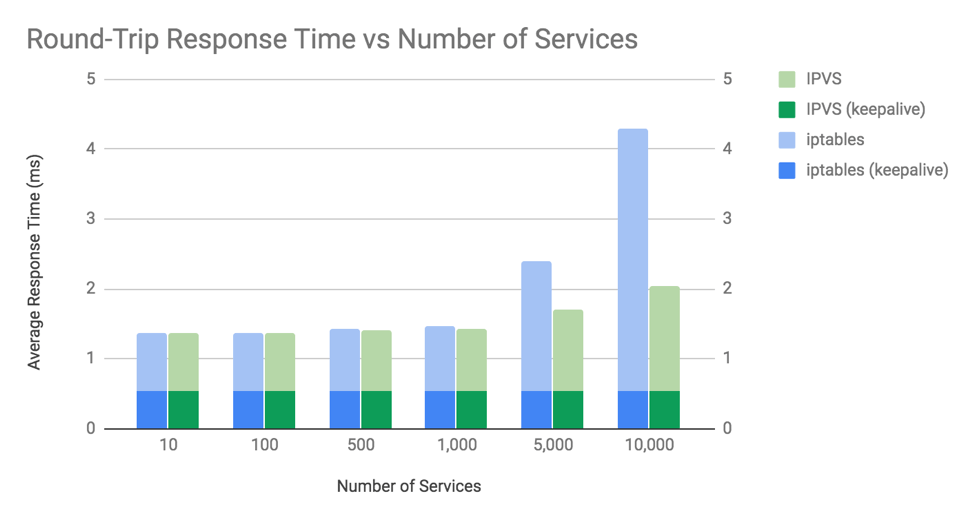 图片来自:Comparing kube-proxy modes: iptables or IPVS?
图片来自:Comparing kube-proxy modes: iptables or IPVS?
Ingress 与 Gateway
Service 只能在集群内做负载均衡,如果我们的服务需要被外部访问,Service 本身提供了 NodePort 和 LoadBalancer 两种类型的 Service 可以直接对外提供访问。
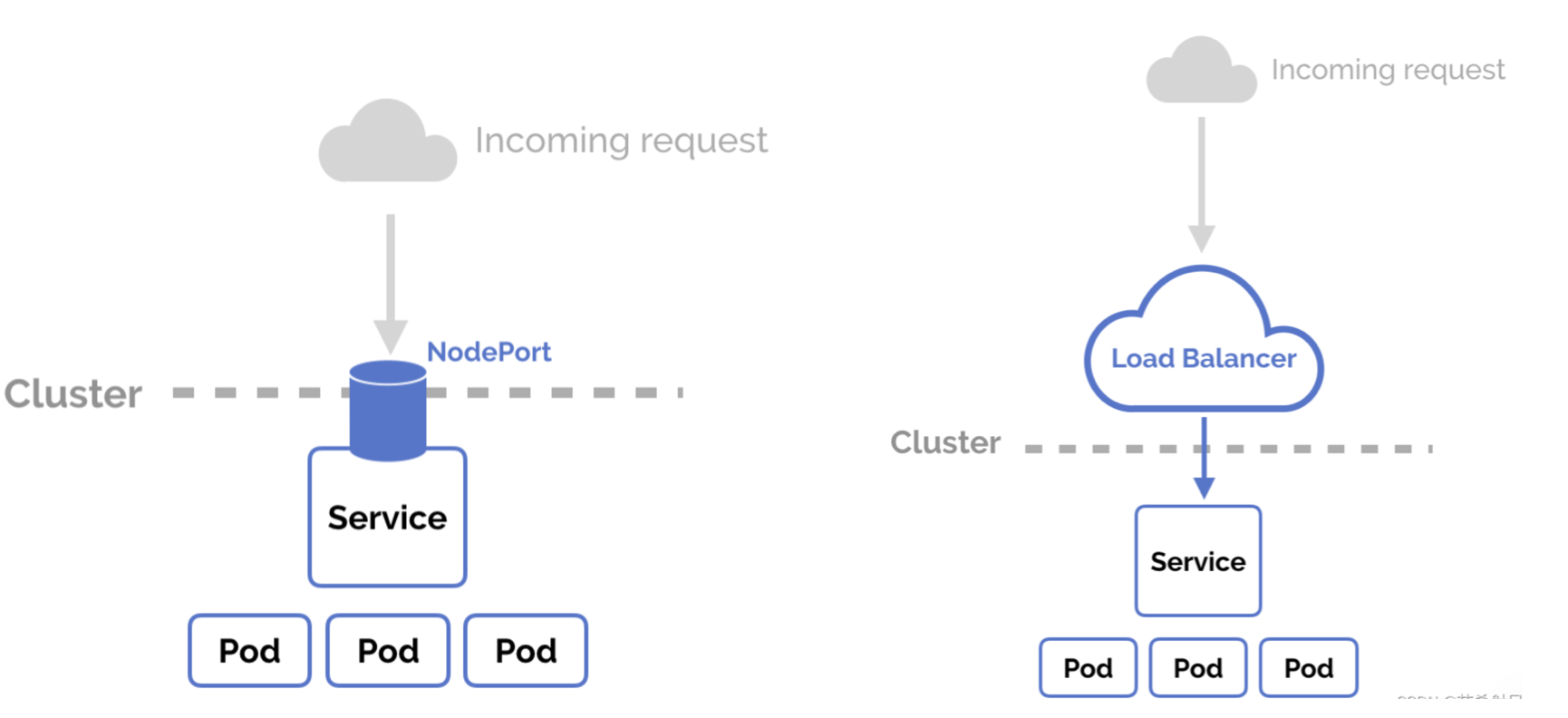
但这种方式有一些局限性:
- NodePort 方式需要在每个节点上开放端口,且端口号范围是 30000-32767 之间,端口数量有限。
- LoadBalancer 方式需要云厂商支持,且每个 Service 都会创建一个负载均衡实例,浪费资源且成本较高。
- 两种方式都只能基于四层(TCP/UDP)做负载均衡,无法基于七层(HTTP/HTTPS)做路由转发。
因此为了解决上述问题,Kubernetes 提供了 Ingress 和 Gateway 两种方式来对外提供服务。我们首先来看下
在 Kubernetes 中部署的服务如果想被外部访问,主要有三种方式:
NodePort Service:在每个节点上开端口供外部访问。
LoadBanlacer Service:使用云厂商提供的负载均衡对外提供服务。
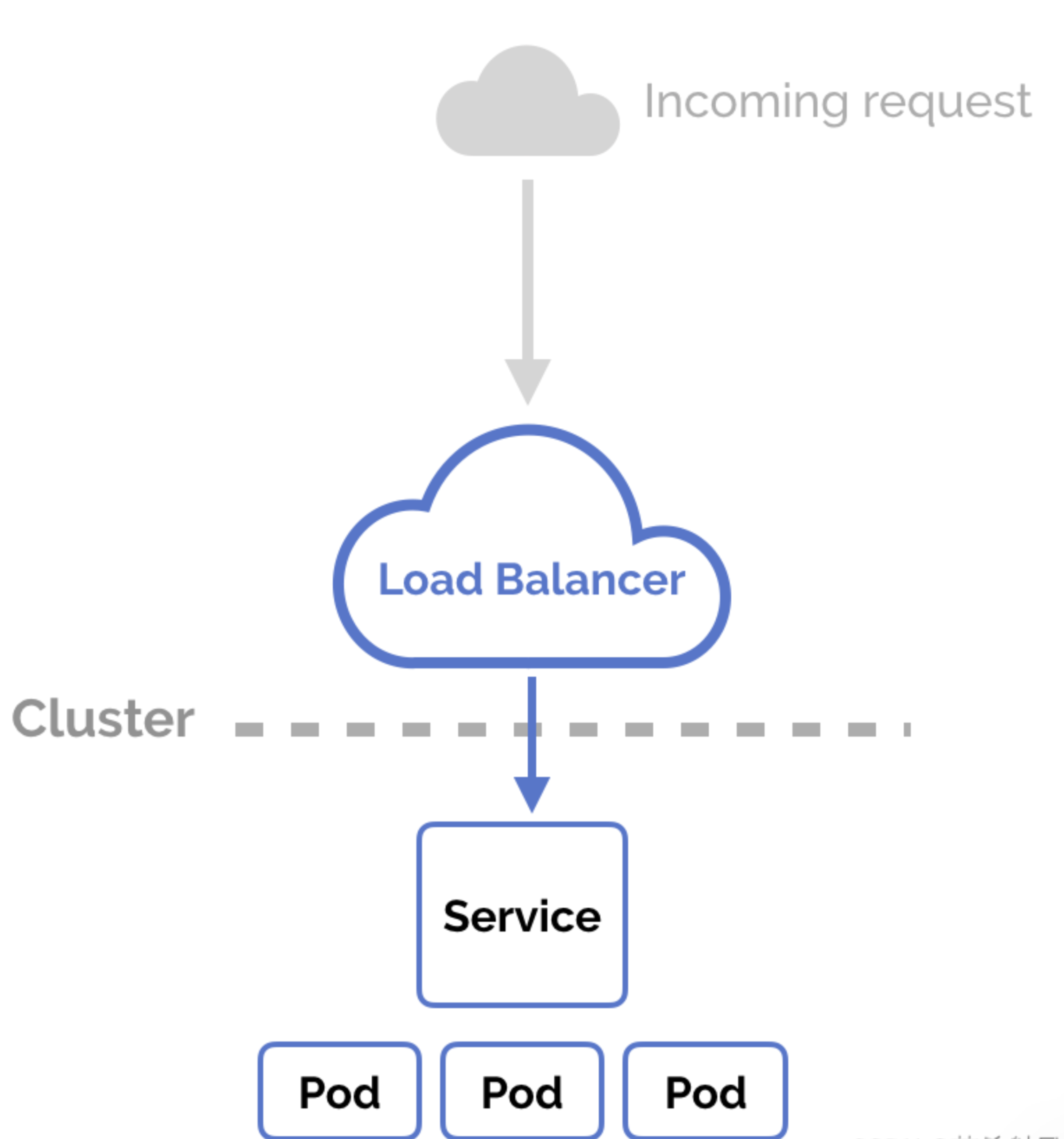
Ingress:Kubernetes 提供的七层流量转发方案。

图片来自 https://matthewpalmer.net/kubernetes-app-developer/articles/kubernetes-ingress-guide-nginx-example.html
Ingress 就是“服务的服务”,本质上就是对反向代理的抽象。Ingress 的使用需要 Ingress Controller,可以安装标准的 Nginx Ingress Controller,相当于在 Kubernetes 里装一个 Nginx 为业务服务做反向代理负。
Ingress 示例如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
- Host: 配置的 host 信息,如果为空表示可以接收任何请求流量。如果设置,比如上面规则设置了 "foo.bar.com" 则 Ingress 规则只作用于请求 "foo.bar.com" 的请求。
- pathType: 必填字段,表示路径匹配的类型。
- Exact:精确匹配 URL 路径,且区分大小写。
- Prefix:基于以 / 分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由 / 分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。

Ingress 创建后相当于在 Nginx Ingress Controller 里面创建配置,和我们日常使用 Nginx 添加配置没有区别。
## start server *.foo.com
server {
server_name *.foo.com;
listen 80;
set $proxy_upstream_name "-";
listen 443 ssl http2;
# PEM sha: 2d165d45c7f24c8a4df64a740666f02378fc8828
ssl_certificate /etc/ingress-controller/ssl/default-fake-certificate.pem;
ssl_certificate_key /etc/ingress-controller/ssl/default-fake-certificate.pem;
location ~* "^/foo" {
6.1 fanout
所谓 fanout 指的是在同一个域名下,基于 HTTP URL 匹配将请求发送给不同的服务。

apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
6.2 常用注解
rewrite-target
用来重定向 URL
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: rewrite
namespace: default
spec:
rules:
- host: rewrite.bar.com
http:
paths:
- backend:
serviceName: http-svc
servicePort: 80
path: /something(/|$)(.*)
在此入口定义中,需要在 path 用正则表达式匹配字符,匹配的值会赋值给 $1、n 等占位符。在上面的表达式中 (.*) 捕获的任何字符都将分配给占位符$2,然后将其用作 rewrite-target 注释中的参数来修改 URL。
例如,上面的入口定义将导致以下重写:
- rewrite.bar.com/something 重写为 rewrite.bar.com/
- rewrite.bar.com/something/ 重写为 rewrite.bar.com/
- rewrite.bar.com/something/new 重写为 rewrite.bar.com/new
App Root
重定向时指定对于在 “/” 路径下的请求重定向其根路径为注解的值。示例如下,注解值为 /app1 则请求 URL 由原来的的 / 重定向为了 /app1。
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/app-root: /app1
name: approot
namespace: default
spec:
rules:
- host: approot.bar.com
http:
paths:
- backend:
serviceName: http-svc
servicePort: 80
path: /
检查
$ curl -I -k http://approot.bar.com/
HTTP/1.1 302 Moved Temporarily
Server: nginx/1.11.10
Date: Mon, 13 Mar 2017 14:57:15 GMT
Content-Type: text/html
Content-Length: 162
Location: http://stickyingress.example.com/app1
Connection: keep-alive
上传文件限制
外部通过 Nginx 上传文件时会有上传大小限制,在 Nginx Ingress Controller 中该限制默认是 8M,由 proxy-body-size 注解控制:
nginx.ingress.kubernetes.io/proxy-body-size: 8m
可以在创建 Ingress 时设置
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: 80m
name: gateway
namespace: default
spec:
rules:
...
6.4 启用TLS
部署好 NGINX Ingress Controller 后,它会在 Kubernetes 中开启 NodePort 类型的服务,
$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.107.127.108 <none> 80:32556/TCP,443:30692/TCP 25d
ingress-nginx-controller-admission ClusterIP 10.111.3.4 <none> 443/TCP 25d
当我们从外部访问该端口时请求就会根据 Ingress 规则转发到对应的服务中。为了数据安全,外部到服务的请求基本上都需要进行 HTTPS 加密,和我们在没用 Kubernetes 时需要在主机上配置 Nginx 的 HTTPS 一样,我们也需要让我们的 Ingress 支持 HTTPS 。
以自签名证书为例,配置 Ingress 支持 HTTPS 分三步:
生成证书
$ openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 \
-keyout tls.key -out tls.crt -subj "/CN=foo.bar.com/O=httpsvc"
创建 TLS 类型的 secret
$ kubectl create secret tls tls-secret --key tls.key --cert tls.crt
secret "tls-secret" created
创建 ingress 并设置 TLS
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: nginx-test
spec:
tls:
- hosts:
- foo.bar.com
# This assumes tls-secret exists and the SSL
# certificate contains a CN for foo.bar.com
secretName: tls-secret
rules:
- host: foo.bar.com
http:
paths:
- path: /
backend:
# This assumes http-svc exists and routes to healthy endpoints
serviceName: httpsvc
servicePort: 80
这样在请求 foo.bar.com 时就可以使用 HTTPS 请求了。
$ kubectl get ing ingress-tls
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-tls <none> foo.bar.com 192.168.64.7 80, 443 38s
$ kubectl get ing ingress-tls | grep -v NAME | awk '{print $4, $3}'
192.168.64.7 foo.bar.com
编辑 /etc/hosts ,加入 192.168.64.7 foo.bar.com
$ curl -k https://foo.bar.com
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
DNS for Service
Kubernetes 中 Service 的虚拟 IP、Port 也是会发生变化的,我们不能使用这种变化的 IP 与端口作为访问入口。K8S 内部提供了 DNS 服务,为 Service 提供域名,只要 Service 名不变,其域名就不会变。
Kubernetes 目前使用 CoreDNS 来实现 DNS 功能,其包含一个内存态的 DNS,其本质也是一个 控制器。CoreDNS 监听 Service、Endpoints 的变化并配置更新 DNS 记录,Pod 在解析域名时会从 CoreDNS 中查询到 IP 地址。 
7.1 普通 Service
对于 ClusterIP / NodePort / LoadBalancer 类型的 Service,Kuberetes 会创建 FQDN 格式为 $svcname.$namespace.svc.$clusterdomain 的 A/AAAA(域名到 IP) 记录和 PRT(IP到域名) 记录。
$ kubectl get svc kubia
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia ClusterIP 10.99.166.60 <none> 80/TCP 47h
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
kubia-5bb46d6998-jjlgn 1/1 Running 0 2m25s
kubia-5bb46d6998-jtpc9 1/1 Running 0 14h
kubia-5bb46d6998-mnlvj 1/1 Running 0 2m25s
~ nslookup kubia.default
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubia.default.svc.cluster.local
Address: 10.99.166.60
~ nslookup 10.99.166.60
60.166.99.10.in-addr.arpa name = kubia.default.svc.cluster.local.
7.2 Headless Service
对于无头服务,没有 ClusterIP,Kubernetes 会对 Service 创建 A 记录,但返回的所有 Pod 的 IP。
~ nslookup kubia-headless.default
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubia-headless.default.svc.cluster.local
Address: 10.44.0.6
Name: kubia-headless.default.svc.cluster.local
Address: 10.44.0.5
Name: kubia-headless.default.svc.cluster.local
Address: 10.44.0.3
7.3 Pod
对于 Pod 会创建基于地址的 DNS 记录,格式为 pod-ip.svc-name.namespace-name.svc.cluster.local
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubia-5bb46d6998-jtpc9 1/1 Running 0 28h 10.44.0.3
bash-5.1# nslookup 10.44.0.3
3.0.44.10.in-addr.arpa name = 10-44-0-3.kubia-headless.default.svc.cluster.local.
3.0.44.10.in-addr.arpa name = 10-44-0-3.kubia.default.svc.cluster.local.