日志
日志分类
日志记录系统运行期间发生的离散事件,在实际工程中,按用途来说大致有三类日志:
- 访问日志:系统每次收到请求时记录的日志。
- 应用日志:开发人员在开发阶段写入的,用来记录系统运行期间发生过的关键离散事件的日志。
- 调用链追踪日志:一次请求在整个系统的完整调用情况,是分布式系统中进行问题排查、性能分析最重要的手段。
CNCF 的可观测性白皮书将日志细化为了五类:
应用日志(Application Log):应用中的事件日志,帮助开发者理解和 debug 应用。
安全日志(Security Log):安全相关事件时打印的日志,比如记录登录失败、密码修改、认证失败等事件。
系统日志(System Log):操作系统内核级别的事件日志。比如系统的 syslog、journald日志 等。
审计日志(Audit Log):也称为(Audit trail)记录事件的详情,包括事件类型、执行的操作、发起人以及系统响应情况等,用于后续审计分析。
基础设施日志(Infrastructure Log):涵盖整个基础设施层面的日志收集,包括主机、网络、存储等各个层面的日志。
这里笔者只对访问日志和应用日志做相关介绍,链路追踪日志在下一篇链路追踪讨论。
访问日志
日志格式
对于访问日志,工业界标准为来自美国国家超级计算机应用中心(NCSA)的 Common Log Format,这也是 Apache 使用的日志格式。标准格式为
host ident authuser date request status bytes
- host:客户端主机 IP 或域名
- ident:客户端标识,大多数时候是
- - authuser:认证过的用户信息,大多数时候是
- - date:请求时间,一般放在方括号 [] 中,格式为
[day/month/year:hour:minute:second timezone] - request:请求信息,包含 HTTP 方法、请求路径、HTTP 版本
- status:响应状态码
- bytes:响应体大小,单位为字节
如果某个字段不存在,则使用 - 代替,示例如下:
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
下面一条是 Apache 的访问日志,可以看到其格式与标准格式基本一致:
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395
Nginx 的日志格式基本遵循这个规范,但也做了一些扩展。比如增加了 HTTP Referer 和 User Agent 这样的信息,具体参考 Nginx 文档:## ngx_http_log_module 其默认格式为
log_format main '$remote_addr - $remote_user [$time_local] $status '
'"$request" $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
无论是用 Nginx/Apache 还是 Web 服务器、服务框架,生成的访问日志一般需要包含以下信息:
| 字段名 | 含义 |
|---|---|
| 来源主机 | 发出请求的客户端的 IP 或者域名 。如果无法获取则使用 - 代替 |
| 访问用户 | 客户端用于验证身份的用户名或用户 ID。如果不存在值则使用 - 代替 |
| 访问时间 | 请求的时间,格式为 [day/month/year:hour:minute:second timezone] ,比如 [07/Aug/2024:05:48:44 +0000]。通常即使天数日期为一位数,也用两位表示,比如 07 而不是 7。 |
| 请求信息 | 包含请求的方法、请求的路径、请求的协议 |
| 响应状态码 | 响应状态码,比如 200、404 |
| 响应字节数 | 响应体大小,单位为字节 |
| 响应时间 | 执行请求的耗时,单位为毫秒 |
| TraceID(可选) | 请求的 TraceID |
| SpanID(可选) | 请求的 SpanID |
| ParentSpanID(可选) | 请求的父 SpanID,如果当前请求是链路中的第一个请求,则使用 - 代替 |
| headers(可选) | 请求、响应头中的信息,比如 User-Agent、Referer 等,按需选择,注意不要包含认证 token 等敏感信息 |
日志聚合
基于以上格式,可以看到访问日志中包含了请求路径、请求方法、请求的返回状态码、响应时间等信息,基于这些信息做聚合就可以计算出如下关键指标:
- 吞吐量指标:如 m1_rate,m5_rate,m15_rate。即 1 分钟、5 分钟、15 分钟内的 QPS。
- 响应时间统计:计算出 P50、P95、P99 等时间分布统计。
- 状态码分布指标:统计不同状态码的请求数量,分析系统错误情况,当 4XX、5XX 错误率较高时,需要及时告警,分析原因。
- TopN 请求:可以统计访问量最大、访问最慢、错误最多的请求,然后做针对性的分析优化。
应用日志
应用日志主要记录系统运行期间发生过的离散事件,用于在分析故障问题时提供上下文,帮助快速定位问题,因此也被称为诊断日志。
日志格式
应用日志目前没有业界统一的规范,更多的来自于实践反馈。下面是一个参考格式
[时间戳] [日志级别] [模块名] [进程ID] [线程ID] [TraceID | SpanID | ParentSpanID] [错误码] [错误信息] [文件名] [文件行号]
时间戳
日志产生的时间戳,一般取应用所在机器的本地时间,精确到毫秒。格式为 [yyyy-MM-dd HH:mm:ss.SSS]。
日志级别
标识日志的重要程度,由高到低通常为 错误(ERROR)、警告(WARN)、信息(INFO)、调试(DEBUG)四类,分别用于:
- ERROR:记录错误、异常信息。通常需要立即告警、修复。
- WARN:记录警告信息,比如非致命错误、潜在问题、不当用法等。通常需要引起后续的关注和消除。
- INFO:记录应用运行过程的关键事件,比如操作信息、启动过程、配置变更信息等。
- DEBUG:用于错误分析的调试信息,通常只在开发、调试阶段使用。如果生产需要,也可以动态的将部分日志界别调整到 DEBUG。
更细分的日志级别可以参考 log4j,其有如下等级:
| 日志级别 | 含义 |
|---|---|
| ALL | 打印所有日志 |
| TRACE | 更细粒度的 debug 日志,通常在开发、调试阶段使用 |
| DEBUG | 用于输出详细的调试信息,比如函数的入参、返回值,事件的详细信息等。 |
| INFO | 记录关键事件,比如重要状态的变化、系统启动、服务运行期间的重要事件等。 |
| WARN | 记录警告信息,比如非致命错误、潜在问题、不当用法等。 |
| ERROR | 记录错误信息,比如系统错误、异常信息等。 |
| FATAL | 记录致命错误信息,比如程序崩溃、系统宕机等。 |
| OFF | 最高级别,用于关于日志 |
大部分情况下,生产环境中日志级别使用 INFO 即可,TRACE 和 DEBUG 信息量太大,除了少数关键核心业务,不建议在生产环境中使用。另外在打印 Error/Fatal 级别的日志时,通常需要伴随着事件告警,及时通知相关人员处理错误。
模块名
通常是服务名,标识日志所在的业务和服务模块。比如是商户服务、订单服务等。
进程ID/线程 ID
日志所属进程和线程的ID,通常为应用的进程ID 或进程名。
TraceID/SpanID/ParentSpanID
请求的 TraceID、SpanID、ParentSpanID,如果当前日志与请求无关,则使用 - 代替。
错误码/错误信息
错误码,如果当前日志与错误无关,则使用 - 代替。
文件名/文件行号
产生日志的文件名和行号,通常为应用代码的文件名和行号。
注意事项
想清楚目的后再打印日志,避免打印一切的冲动,日志打印代码本身会消耗资源、影响性能;过多的日志也需要更多的存储空间和更高的查询时间。
只打印关键信息,比如追踪诊断信息、重要事件(比如账户金额变更)、启动时输出配置信息等。
避免打印敏感信息,比如请求中的 token,用户的敏感信息。
日志信息的描述要清晰简洁,方便后续的阅读分析。
日志数据收集清晰后需要进行统一存储,并提供基于关键字的上下文查询,方便后续的分析。
通常日志数据的时效性较低且数据量较大,因此要定期 rotate,将旧的日志数据做清理或归档。如果归档,可以采用冷热架构,将旧的日志数据归档到冷存储中,以节省存储成本。
日志存储
在日志存储领域,ElasticSearch 是一个广泛使用的解决方案,几乎已经是事实上的标准,接触过的同学相信一定对术语 ELK(ElasticSearch、Logstash、Kibana) 不陌生,它们都是 ElasticSearch 公司的产品,加上其用于收集指标日志的 Beats 系列组件,形成了一套完整的日志处理解决方案。
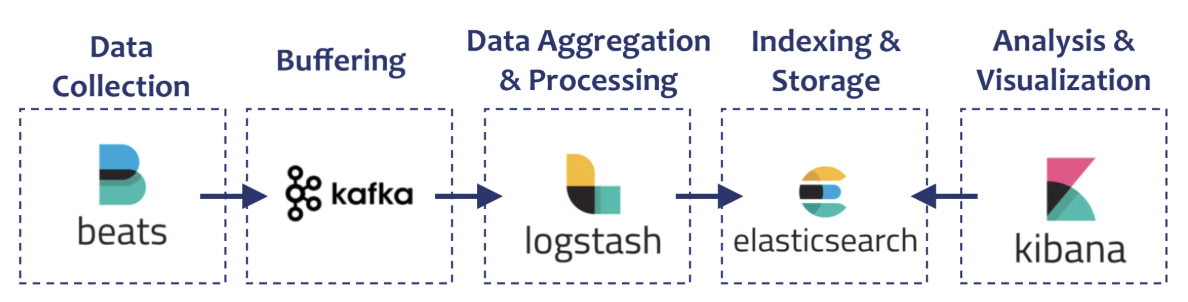
上述技术栈的核心就是 ElasticSearch,其诞生和发展历程也是一个传奇。据说创始人 Shay Banon 是为了要当厨师的妻子开发一个方便搜索菜谱的应用接触了 Apache Lucene,但因为 Lucene 的使用门槛较高,于是 Shay Banon 便在 Lucene 的基础上不断开发优化,最终推出了 ElasticSearch,并且成立公司后在 2018 年上市,市值达到 50 亿美元,实在是技术人之楷模。
倒排索引 Inverted index
Apache Lucene 使用倒排索引来实现高效的全文检索。我们以书籍为例介绍下倒排索引,在大部头教科书中,一般会有两种方便我们快速查找内容的索引:
- 目录:章节和页码的对应关系。
- 索引:关键词和页码的对应关系。

书的目录就是类似于正排索引,代表文档 ID 到内容的映射。
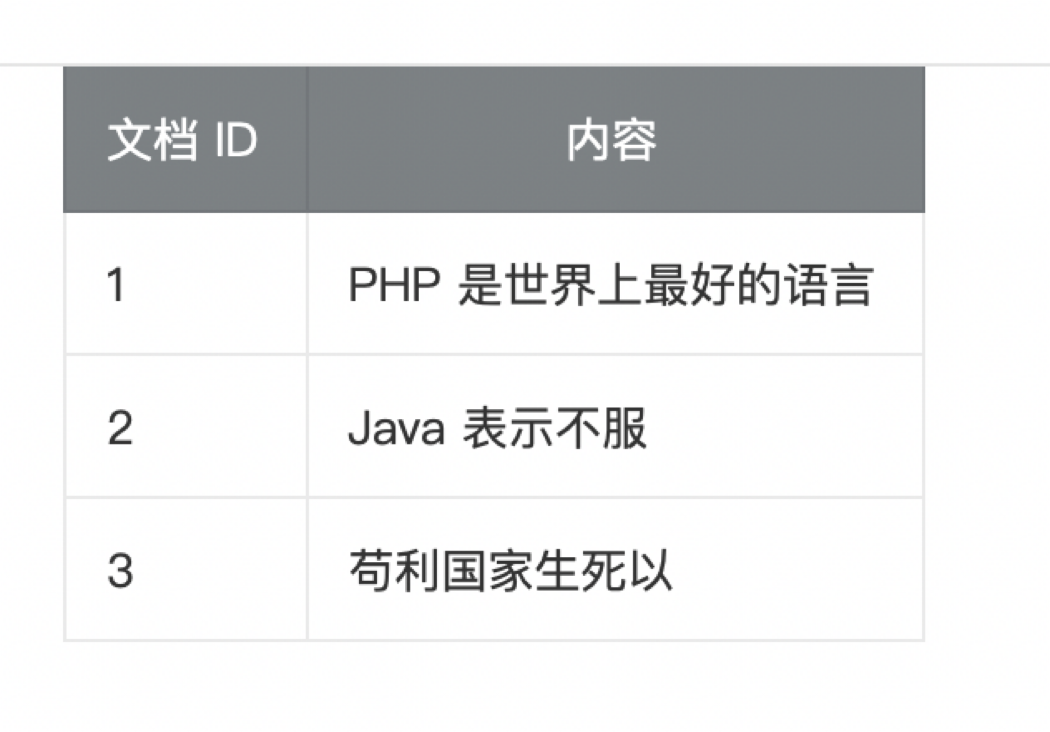
倒排索引相当于书的索引,是内容到文档 ID 的映射。
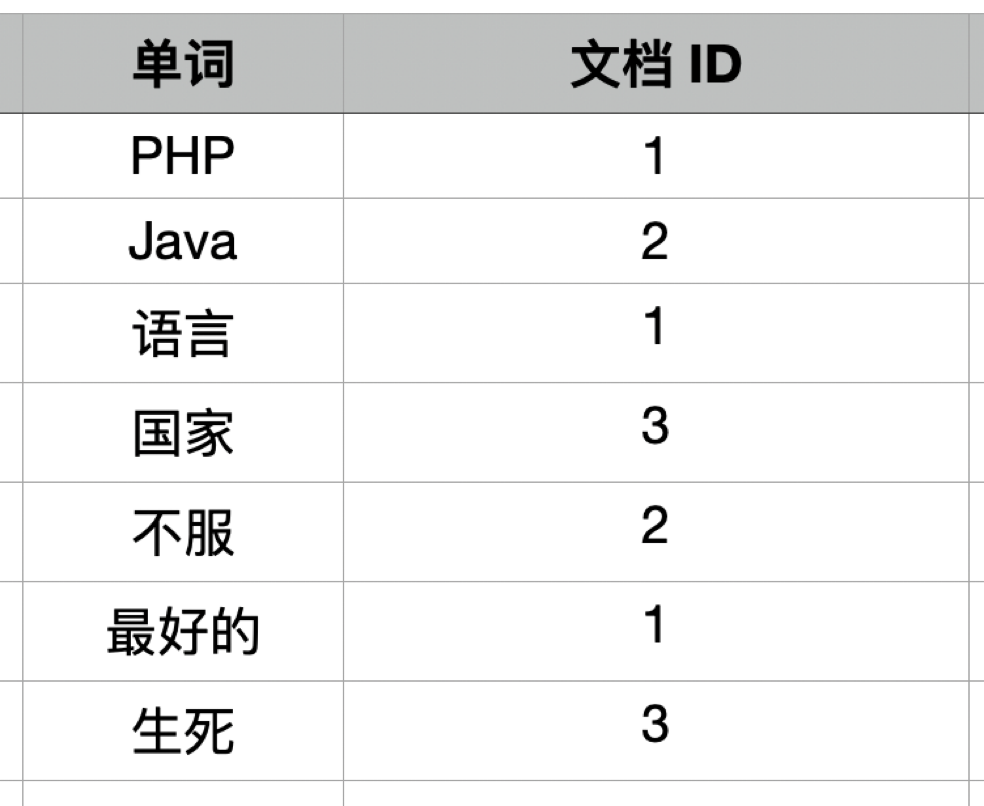
倒排索引的核心有两部分:
- 分词词典(Term Dictionary):分词后的关键词词典以及关键词到倒排列表项的关联信息。
- 倒排列表(Posting List):记录关键词所关联文档的位置信息。
这样在查询的时候,通过关键词获取到倒排列表项,然后根据倒排列表项中文档 ID 的位置信息,就可以快速定位到具体的文档内容,从而实现全文检索。