什么是可观测性
可观测性(Observability)一词来源于控制论,用来衡量通过系统的外部输出推测了解其内部状态的程度。
Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. In control theory, the observability and controllability of a linear system are mathematical duals.
可观测性是一种度量,它衡量的是在多大程度上能够通过系统的外部输出来推断系统的内部状态。 在控制理论中,线性系统的 可观测性 与 可控性 是一对数学上的对偶概念。
--- 维基百科
软件工程借鉴了这一概念,强调通过收集程序的运行情况、内部状态以及组件之间的通信情况,从而得知系统的整体健康状态。2017 年,Peter Bourgon 在文章 Metrics, tracing, and logging对可观测性做了总结。从数据层面将可观测性收集的数据分为三类,并总结了三者的定义、特征以及差异。
指标(Metrics):这是一系列可聚合的数值数据,通常是时间序列数据。它们可以用来衡量系统的性能、健康状况和容量等方面。指标通常是定期收集的,并且可以通过图表或仪表盘进行可视化。
事件日志(Logs):日志记录系统运行期间发生的离散事件。它们通常是文本格式的,包含时间戳、事件级别、消息和其他上下文信息。日志可以帮助开发人员和运维人员了解系统的行为和状态。
链路追踪(Tracing):追踪处理的是请求级别的数据,记录了请求在系统中流转的路径。它可以帮助开发人员了解请求的延迟、瓶颈和错误等问题。追踪通常是通过在代码中插入标记来实现的,这些标记可以捕获请求的开始和结束时间,以及相关的上下文信息。
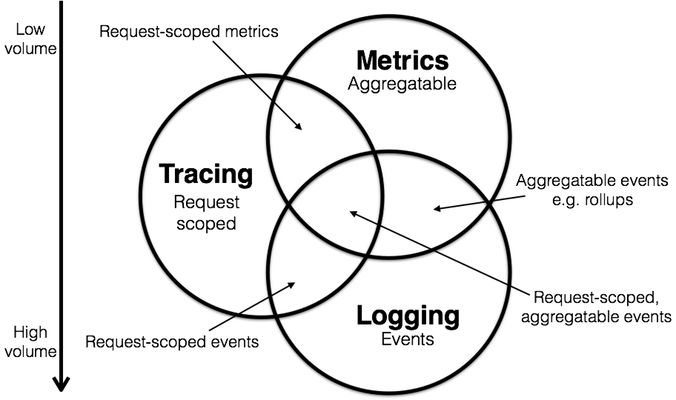
图片来自:Metrics, Tracing, and Logging
2021 年,CNCF 的 Observability Whitepaper(可观测性白皮书) 将上述数据统称为 Signal(信号),除了以上三种,又提出来额外两种信号:
性能剖析(Profiling):对运行中服务的性能剖析,帮助工程师了解应用的运行性能和资源使用情况,从而识别代码级别的性能瓶颈。它通常提供了 CPU、内存、I/O 、GPU等资源的使用情况,以及函数调用的时间分布,分析结果通常以火焰图的形式呈现。
核心转储(Core Dumps):相当于程序崩溃时的快照。当程序异常退出时,系统需要记录下程序的关键信息,比如内存使用、堆栈信息等,将其存入一个核心文件(core file)中,以便工程师通过分析文件,定位问题。
在笔者的实际工程实践中,只接触过对前三种数据的收集、清洗、存储、查询、展示和告警处理,对于性能剖析和核心转储,只在某些特定场景下了解过,比如手动获取 Java 程序的 Heap Dump、通过 perf 获取数据后,分析结果通常以火焰图的形式呈现。但还没有以工程的形式实现,因此后续只针对指标、日志、追踪这三者数据做简要探讨。