Aurora 主要做了三方面的改进:
- 大规模集群化的持久化保证
- 日志即数据库
大规模集群下的持久化
跨 Availability Zone 的 Quorum 机制
为了提高可用性,数据需要被备份到多个节点,但这会带来数据一致性问题。在分布式系统中,该问题通常是通过 quorum 机制来解决。
Quorum 机制(法定人数机制) 是指在分布式系统中,必须有至少一定数量的节点同意某个操作,该操作才会被执行。为了满足一致性要求,quorum 机制需要满足以下条件:
假设有 n 个节点,写入需要 w 个节点确认,读需要至少 r 个节点确认,则
- w + r > n:如果满足,说明读节点和写节点肯定是有交集的,因此读节点中一定有节点包含最新值。
- w > n/2:表示至少有一半以上的节点写入成功,从而保证数据读取时一定会读到最新的数据。
一个常见的节点设置是 n 为 3 或 5,w = r = n/2 + 1。
Quorum 机制的不足
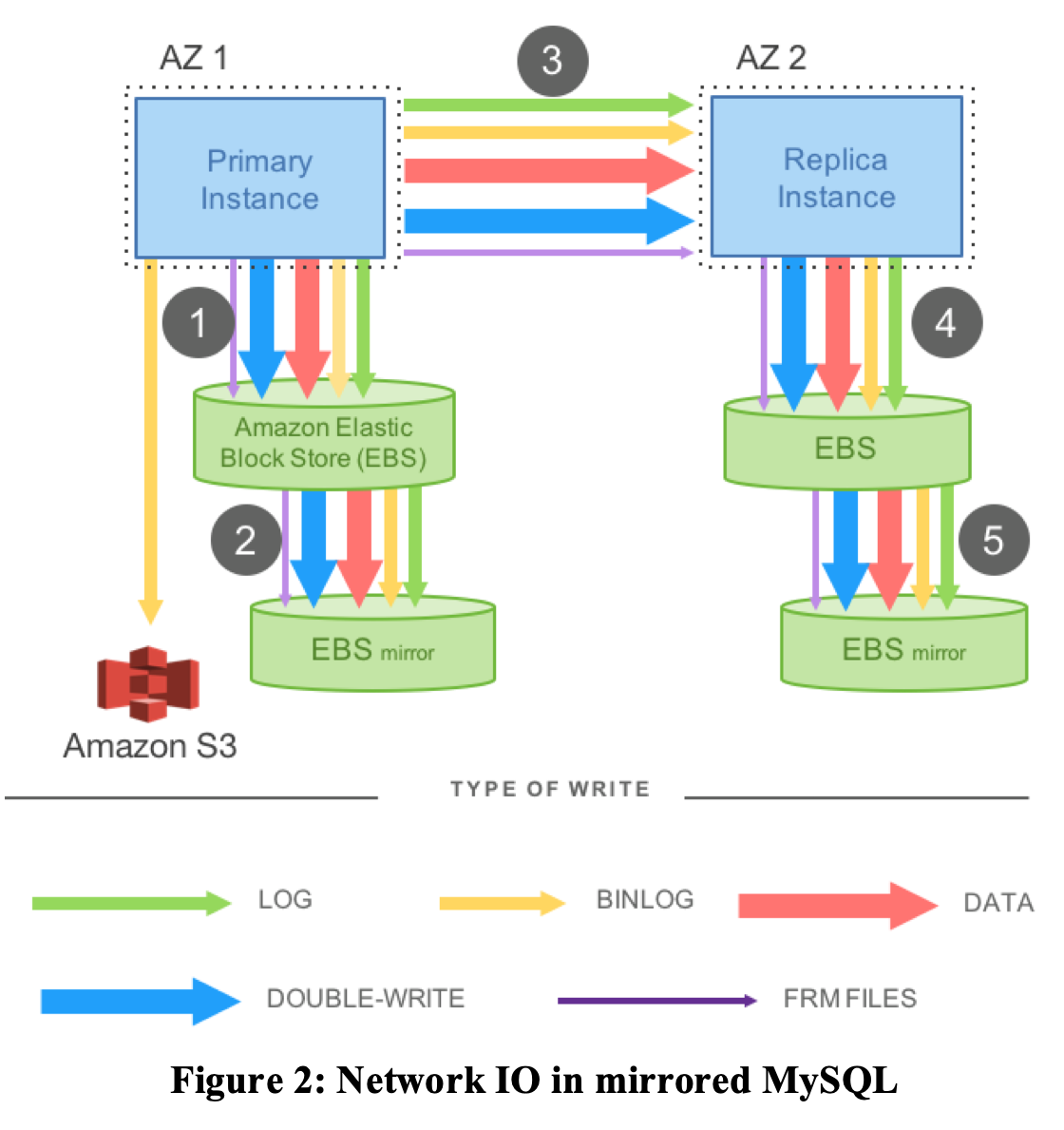
AWS 有可用区(AZ,Availability Zone)的概念,每个 AZ 相对独立,但共享低延迟网络。
上面提到的 Quorum 机制无法应对可用区级别的故障。如果 n 个节点在同一个 AZ 中,那么当 AZ 发生故障时,所有节点都会受到影响,服务将完全不可用。如果 n 个节点分布在 a、b、c 三个 AZ 中,那么当 a 可用区发生故障时,Quorum 机制也会失效。
为了解决上述问题,Aurora 引入了 3 可用区 + 6 副本的 Quorum 机制:
- 每个数据有 6 个副本,分布在 3 个 AZ 中(每个 AZ 内 2 个副本)
- 写 Quorum 需要 4 个副本确认
- 读 Quorum 需要 3 个副本确认
这种跨 AZ 的 Quorum 机制可以做到:
- 对于写操作,可以容忍任意两个节点发生故障。比如某个 AZ 完全失效,或者两个 AZ 中分别有一个节点发生故障。
- 对于读操作,可以容忍任意一个 AZ + 任意一个节点发生故障。
分段存储 & 快速恢复
我们通常用如下公式来衡量系统的可用性:
Availability = MTTF(Mean Time To Failure) / (MTTF + MTTR(Mean Time To Recovery))
在分布式系统中,故障是必然的且难以预测的,因此为了提高系统的可用性,需要尽可能减少故障的恢复时间。为了方便快速恢复,Aurora 采用了**分段存储(Segmented Storage)**的机制。Aurora 将数据切分为 10GB 大小的段,每 6 个段组成一个 保护组(PG,Protection Group),组中的 Segment 分布在 3 个 AZ 中,每个 AZ 有两个 Segment。保护组存储在挂载了 SSD 的 EC2 实例中,众多 PG 组成一个存储卷(Volume),Volume 最大容量为 60TB(注:新版本已经支持到了 128TB)。
Aurora 以 Segment 为单位进行故障恢复,在 10Gbps 带宽下,恢复一个 Segment 只需要大约 10 秒钟的时间。在这种情况下,如果存在故障导致 Quorum 机制失效,需要在 10s 内出现以下故障:
- 同时发生 2 个不相关的故障
- 与故障不相关的 AZ 发生故障
在实际场景中,这种故障发生的概率非常低。因此 Aurora 也宣称提供了 99.99% 的可用性。
弹力设计的优势
引用论文中的话:
Once one has designed a system that is naturally resilient to long failures, it is naturally also resilient to shorter ones. A storage system that can handle the long-term loss of an AZ can also handle a brief outage due to a power event or bad software deployment requiring rollback 如果你设计了一个能够容忍长期故障的系统,那么它自然也能够容忍短期的故障。一个能够容忍 AZ 长期故障的存储系统,也能够容忍由于电源故障或软件部署失败导致的短暂故障。
Aurora 的弹力设计可以为运维带来非常大的便利性。比如如果某个节点成为了 hot node,那么可以节点中的 segment 或者整个节点标记为不可用,然后快速将 segment 迁移到其他节点。或者某些节点需要进行软件升级、打补丁等操作,也可以按计划在 AZ 中进行,甚至可以使用 CICD 来实现快速发布。
日志即数据库
写放大